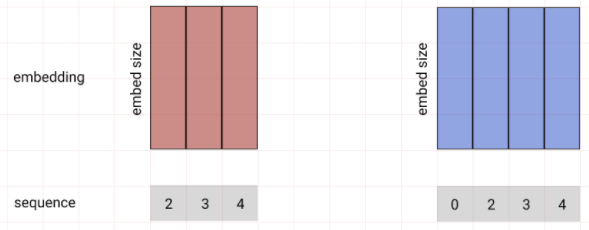
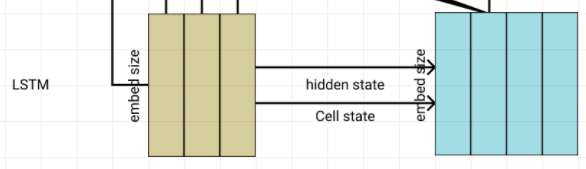
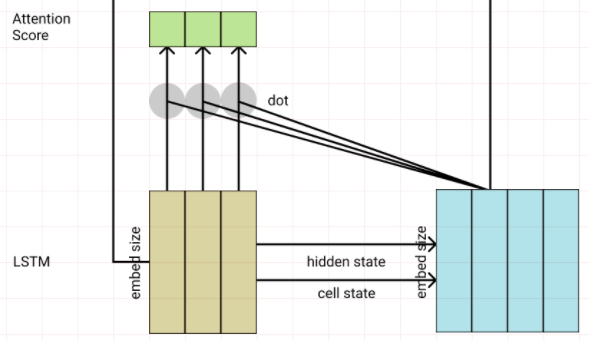
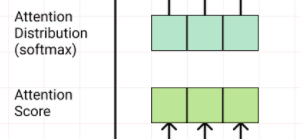
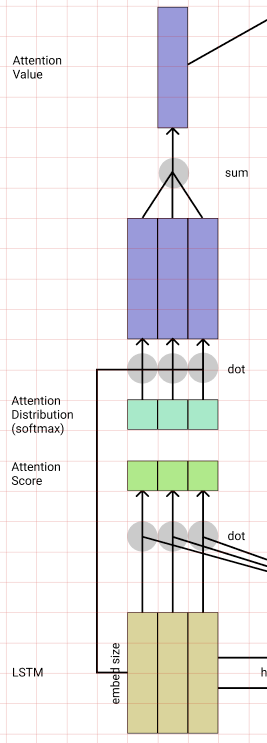
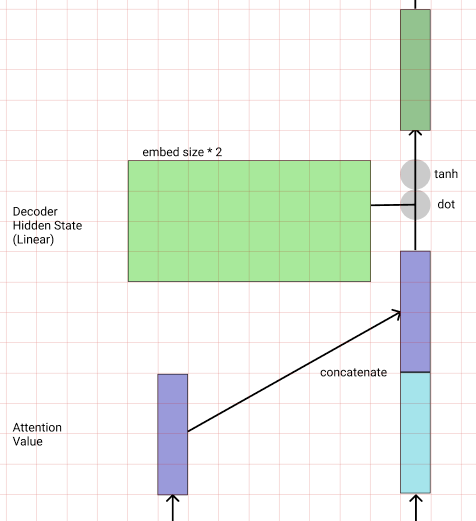
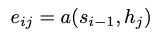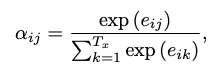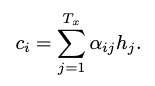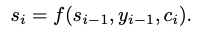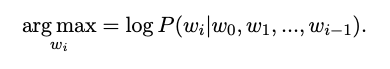단어를 생성하는 방법으로 의미 해석 레이어를 달아 어떤 단어를 선택할지 결정하는 Linear레이어와 Softmax로 단어의 Sequence를 뽑게 만들었다.
# wy (output)
wy = nn.Linear(embed_size, tar_n_vocab) # (embed_size, word_cnt)
# softmax (nll_loss로 연산하기 위해 log_softmax)
x = F.log_softmax(x, dim=2)
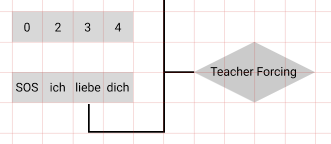
Teacher Forcing
일반적으로 교사강요 라고 해석하는 것 같다.
Seq2seq 모델에서 RNN에서 나온 출력을 다음 step의 입력으로 넣어주는 구조로 출력 리스트를 만들어 낸다. (추론)
이러한 모델을 학습시킬때 step중간에서 원하는 출력이 나오지 않으면 다음 step에 원하는 입력을 주지 못할 것이고 해당 시점 이후로 모든 값이 틀려 버릴 수 있다.
이러한 문제 때문에 RNN의 모든 step에서 입력으로 정해진 값만 입력으로 넣어주는 방법을 교사강요라고 한다.
하지만 이방법을 과하게 이용할 경우, 테스트시 사용될 방식인 추론과 교사강요를 통한 학습의 생성 방식의 차이로Exposure Bias Problem (노출 편향) 문제가 발생한다.
이게 어떤 문제인지 조금 상상해보자면 Embedding된 단어의 의미를 이용하여 다음 출력에 대한 추론을 해야하고 이는 목표출력과 Embedding 거리와 가까운 출력을 낼 수 있을 것 같은데, 그때 이 출력이 입력으로 들어가여 학습하면 해당 주변의 단어에 대하여 유연한 추론이 가능 할 것이라고 생각된다. 그렇기에 Teacher Forcing을 이용하면 이러한 유연성을 학습할 수 없다는 문제가 있지 않을까 생각해봤다.
아무튼 이러한 이슈 때문에 랜덤확률로 Teacher Forcing사용을 조절하는 방법을 사용하거나, 정확성이 부족한 초반에만 사용하는 방식등이 있는 것 같다.
하지만 이러한 노출편향 문제가 사실 별로 큰 영향을 끼치지는 않는다는 논문이 이후 발표되어 있긴 하다.
친구를 대신하여 대화상대가 되어 줄 수 있는 대화 봇을 만들 수 없을까 생각하며, 데이터베이스, 음성 생성 엔진 기반 대화봇을 만들었었다.
2019년
진짜 사람처럼 SNS를 관리하고 이용하는 인공지능을 만들어 보고자 생각했었다.
실제로 페이스북 같은 인스타그램 계정을 운영하면서 캐릭터 컨셉에 맞는 게시물을 올리고 채팅을 칠 수 있다면 분명 재밌을 것 이라고 생각했다.
2020년
AI분야로는 많이 부족한 나에겐 일단 AI를 SNS에 올릴 수 있는 플랫폼 코드를 구현하며 SNS관련 API를 숙달했다.
2021년
20년도 초 부터 운영해 오던 인공지능 동아리에서 조금이나마 AI에 대한 지식을 쌓았고, 무작정 챗봇 개발에 돌입했다.
그렇게 공부도중 9월 대한민국 육군 특공대에 입대를 하게 되었다.
2022년
조금씩 짬내서 이렇게 글도 쓰고 프린트한 논문들도 가끔씩 읽고 있다. (정말가끔)
2023년
전역예정이다.
오픈 도메인 챗봇 만들기 정리해보자!
우선 필자는 많은 개발자들이 그렇듯 독학을 통해서 공부와 포스팅을 하고있고,
스스로도 전문성은 많이 떨어질 것 이라고 인지하고 있다.
그렇기에 [한국어 오픈도메인 챗봇] 시리즈는 재미로만 보면 좋을 것 같다.
뭘 만드려고 하나
필자의 최종적인 목표는 AI 캐릭터를 만들어 내는 것이다.
이 프로젝트는 그중 대화 부분에 해당되는 부분을 공부하고 구현해 보려고 한다.
나는 오픈도메인 챗봇을 만들기를 희망한다.
챗봇은 크게 이렇게 2개로 나뉘는 것 같다.
1. task oriented chatbot
2. open domain chatbot
이 두개를 간단히 설명하자면,
1번은 목적 지향 대화 챗봇으로, 보험추천 챗봇 같은 문제 해결에 중심을 두고 있는 챗봇을 말하고,
2번은 오픈된 대화주제 챗봇으로, 세상에 존재하는 모든 것을 대화 소재로 하는 대화가 가능한 챗봇을 말한다.
나는 여기서 2번의 open domain chatbot을 만들어보기를 희망하고 있다.
위에 설명한 것 과 같이 많은 범위를 포괄 해야함으로 넓은 범위의 지식을 알고 여러가지 상황에 flow대로 대처하는 것이아닌 유연하게 대처가 가능한 챗봇을 만들 수 있어야 한다.
어떤 기술이 필요할까?
섬세한 챗봇을 만들기 위해서는 너무나 많은 기술을이 필요하고, 특히 언어에 대한 분야는 아직까지도 상당히 난이도가 높다고 평가 되는 것 같다.
어려운 점.
챗봇 만들기를 준비하면서 개인적으로 어려웠던 점을 떠올려봤다.
첫번째로는 채팅 데이터를 얻는것이 가장 어려운 점이라고 생각했다.
한국어 채팅데이터와, 원하는 형태로 라벨링된 대화 데이터를 얻을 수 있는곳은 거의 없었고, 영어 데이터 조차도 찾기 힘들 정도였다.
- 이러한 부분은 역할놀이나 컨셉 랜덤체팅을 지원하는 작은 놀이 웹사이트를 만들어 데이터를 수집해 보면 어떨까 생각도 해봤었다. (라벨링 된 데이터를 얻기 좋다)
- 소설이나 연극 대본 데이터를 잘 처리해서 라벨링된 pair 데이터로 이용할 순 없을까 생각도 해봤다.
두번째로는 학습 리소스와 시간인 것 같다.
현존하는 생성모델들은 거대한 파라미터 수와 방대한 양의 학습데이터를 사용하여 학습하는 경우가 많다. 우리는 이러한 부분을 퓨샷 러닝, 제로샷 러닝, 파인튜닝 등의 기법으로 추가 학습을 최소한으로 하여 모델을 이용 할 수 있긴 하지만, 필자는 훌륭한 학습환경을 마련하기도 힘들고, 긴 학습 시간을 넉넉히 기다리는 것도 쉽지 않다.
세번째로는 난이도가 높다.
개인적인 생각이긴 하다만, AI입문자가 하기에는 높은 난이도의 영역이라고 생각 된다. 현재 연구가 활발하게 진행되고 있다지만 여전히 많은 한계들이 발목을 잡고 있는 상황인 것으로 알고있다. (2021.06) 또한 고성능의 최신 논문이 나왔다 할지라도 리뷰나 구현체 없이 따라해볼 능력까지는 나에게는 아직 조금 어려운 것 같다.
목표.
나의 목표는 감정 묘사와 페르소나 적용이 가능한 챗봇을 만드는 것이지만,
질질 끌기보다는 최대한 가성비 넘치는 방법을 찾아 공부하고 개발하여 빠르게 결과를 보고 피드백 할 수 있는 방법으로 진행 해 보고 싶다.
로드맵
챗봇
메모리 장착
페르소나 장착
일관성 장착
이벤트 장착
플랫폿
플랫폼 연결
이벤트 장착
※ 쓰고나니 하나같이 현 최신 챗봇 연구분야에서도 어려워하는 목표들이다.
최근 읽은 논문들에 의하면 상당히 가성비 넘치는 방법이 많아 보인다. 완벽하진 않지만, 종종 몇번의 소름돋는 짜릿함을 선사하는 대화를 해주는 AI를 만들 순 없을까?
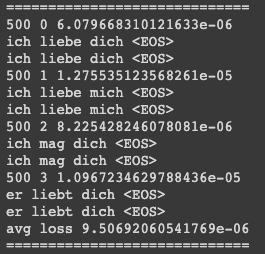
전체 데이터를 모두 CUDA로 만들고 학습을 돌렸을때 -> CPU상태의 데이터를 batch로 받아 연산시에만 CUDA로 바꾸어 쓴다. CUDA가 생각보다 용량이 작고 당장 계산하지 않을 데이터를 CUDA에 넣어놓는것은 비효율적,.. 약간 뻔한 이유
(1)번을 수행했음에도 메모리가 부족한 경우가 있는데 그것은 한 batch에서 너무 많은 데이터를 사용하기 때문이다. batch size를 줄여주자.
cuda 캐시를 비워주는 아래 명령을 이용해보자. 왠만하면 요쯤에서 해결된다.
# cuda delete cache
torch.cuda.empty_cache()
(1, 2, 3)번 모두 했음에도 잘 안되는 경우에는 파이썬 내의 가비지 컬랙터를 이용하여 안쓰는 메모리 정리를 좀 해주자
import gc
gc.collect()
가끔 이걸로 해결된다.
위에가 모두 안될경우 Colab이나 환경 문제일 확률이 크다. colab일경우 런타임을 초기화 했다가. 다시실행하면 되는경우가 많다. 주로 코드에 약간 문제가 있거나, 실행중 interrupt한뒤 에러가 생기는경우 이렇게하면 될확률이 높다. colab아니면... 음... 재설치? 안해봐서 모르겠다.
나는 transformer 모델 돌리다가 위와같은 에러를 만났다.
아참 그리고 좀 골때린 소리처럼 들릴지 몰라도 자료형 때문에 나는 에러가 한번 발생하면, 이유없이 해당에러가 나와서 진행을 못하게 만드는 경우가 있다 pandas환경에서부터 원하는 자료형을 만들어놓고 tensor로 옮기도록 하자. (매우중요!!!)
해당 논문을 원활히 읽기 위해서는 아래의 논문에 대하여 어느 정도 이해가 있다면 편하게 읽을 수 있다.
seq2seq, Transformer, GPT2, TransferTransfo
Abstract
문제점
데이터 부족은 여러 영역에서 task-oriented dialogue system의 빠른 개발을 오랜 시간 방해하는 장기적이고 중대한 과제이다.
* task-oriented dialogue system - 작업(업무) 지향적 대화형 시스템
작업 지향적 대화형 모델 학습을 위한 문법, 구문, 대화 추론, 의사 결정, 언어 생성 작업들을 터무니없이 적은 데이터로 학습할 것으로 예상된다.
목적
해당 논문에서 최근 진행된 언어 모델링 사전 학습과 전이 학습이 이 문제를 해결할 가능성을 보여주려고 한다.
해당 논문은 텍스트 입력만으로 작동하는 작업 지향적 대화형 모델을 제안한다. 이는 명시적 정책(모델 학습을 위한 것들)들과 언어 생성 모듈을 효과적으로 우회한다.
결과
TransferTransfo 프레임워크(Wolf et al., 2019)와 생성 모델 사전 학습(Radford et al., 2019)을 기반으로 ImageNet데이터 세트에서 MultiWOZ의 복잡한 다중 도메인 작업 지향 대화에 대한 접근법을 검증한다.
* MultiWOZ: Wizards of Oz(WOZ)란 크라우드 소싱 환경에서 두 명의 임의의 참여자가 “사용자”와 “에이전트”의 역할을 나누어 대화를 나누며 데이터를 생성하는 형태를 의미한다. MultiWOZ는 호텔, 택시, 레스토랑, 기차 등을 포함하는 7개 영역에서의 예약과 관련된 약 1만여 개의 대화 세션들로 구성된 데이터이다.
우리의 *자동 평가와 인간 평가는 제안된 모델이 강력한 작업별 neural baseline과 동등하다는 것을 보여준다. 장기적으로, 우리의 접근 방식은 데이터 부족 문제를 완화할 수 있고 작업 지향형 대화 에이전트 구성을 서포트할 가능성이 있다.
Summery
요약보다는 공부하는 느낌으로 읽었다. 너무 쉬워서 패스하는 구문 없이 번역하는 느낌으로 꼼꼼히 정리했다.
1. Introduction
통계적 회화 체계는 2개의 메인 카테고리로 얼추 분류할 수 있다.
작업 지향적 모듈식 시스템
오픈 도메인 chit-chat 뉴럴 모델
* chit-chat : 잡담, 수다
전자는 일반적으로 언어 이해, 대화 관리 및 응답 생성과 같은 독립적으로 훈련된 구성 모듈로 구성된다.
이러한 시스템의 주된 목표는 제한적인 도메인과 작업에서 실질적인 가치가 있는 대화 에이전트를 구축함에 있어서 의미 있는 시스템 응답을 제공하는 것이다.
하지만 이러한 시스템을 위한 데이터 수집과 주석은 복잡하다. 시간적으로, 비용적으로 봤을 때 말이다.
그리고 (데이터를) 양도받기 쉽지 않다.
반면 후자인 오픈 도메인 회화 봇은 자유롭게 이용할 수 있는 주석 처리되지 않은 대량의 데이터들을 활용할 수 있다.
많은 말뭉치들(corpora)은 일반적으로 sequence-to-sequence 아키텍처를 사용하여 end-to-end 뉴럴 모델로 학습할 수 있다.
이것은 고도로 데이터 중심적이지만 이러한 시스템은 신뢰성이 낮고 의미 없는 대답을 만들어내기 쉬움으로 실제 회화 애플리케이션의 생산을 방해한다.
이렇듯 해결되지 않은 end-to-end 아키텍처의 이슈 때문에 검색 기반(retrieval-based) 모델로 초점이 이동했다.
작업 특화 애플리케이션에서 검색 기반 모델은
대규모 데이터 셋을 활용하여 좋은 영향을 준다는 장점이 잇었으며,
시스템 응답에 대한 모든 제어가 가능하지만, 높은 확률로 예측이 가능하다는 단점이 있었다.
즉 pre-existing set에 의존적이며 일반적으로 멀티 도메인에 서 부적절하다.
* 즉 검색 시스템의 응답은 대규모 데이터를 이용해 학습할 시 모든 상황에 대한 응답 제어가 가능하지만,
학습 데이터에 따라 너무 뻔한 대답이 나올 확률이 높다는 것이다.
하지만 최근 연구된 GPT, GPT2와 같이 대용량 데이터셋과 대용량 언어 모델은 생성 모델이 작업 기반 대화 애플리케이션을 지원할 수 있을 거란 질문을 다시 열어준다.
최근 연구진은 fine-tuning 된 GPT모델이 개인적인 회화 분야에서 유용할 수 있음을 보였다.
이러한 접근법은 Persona Chat dataset에서 상당한 개선을 이끌고, 회화 도메인 이서 대규모 사전 학습된 생성 모델 사용에 대한 가능성을 보였다.
* GPT pre-trained 모델을 사용하여 작업 기반 대화 애플리케이션을 만들 수 있을 것이라는 가능성 언급
위 논문에서는 일반적인 주제에 대한 대규모 말뭉치 데이터를 사전 학습한 대규모 생성 모델이 작업 지향형 대화형 애플리케이션을 지원할 수 있다는 것을 보이려고 한다.
첫째로 워드 토큰화, 다중 작업 학습, 확률적 샘플링과 같은 다양한 구성 요소를 결합하여 작업 지향 애플리케이션을 지원하는 방법에 대해 논의한다. 그런 다음 명시적 대화 관리 모듈과 도메인별 자연어 생성 모듈을 효과적으로 우회하여 텍스트 입력에서 완전히 작동하도록 모델을 조작하며, 제안된 모델은 전적으로 시퀀스 대 시퀀스 방식으로 작동하며 간단한 텍스트만 입력으로 소비한다.
* 대화 관리 모듈과 자연어 생성 모듈의 콘텐츠를 모델의 텍스트 입력으로 작동 가능하도록 우회한다는 말이다.
dialogue context to text task
Belief 상태, 데이터베이스 상태 및 이전 턴을 포함하는 전체 대화 콘텍스트는 디코더에 원시 텍스트로 제공된다.
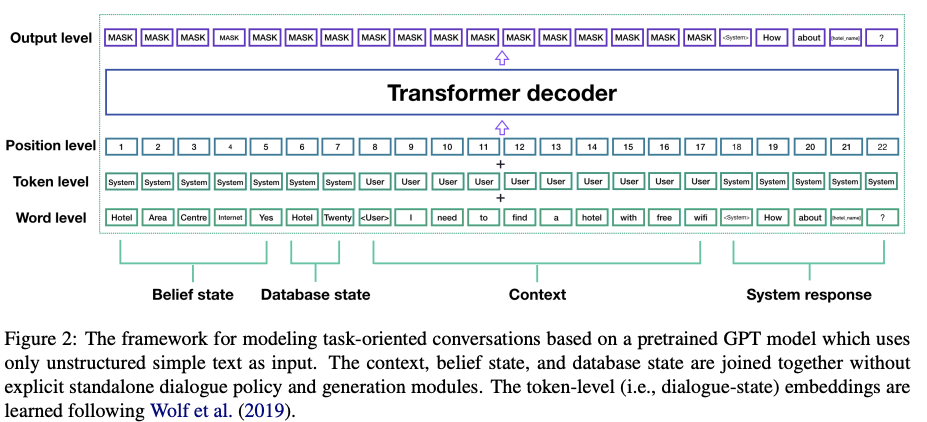
* belief state : 대화의 진행 정보를 저장하는 상태 정도로 이해하면 된다. figure 1을 보면 쉽게 이해할 수 있다.
제안된 모델은 최근에 제안된 TransferTransfo 프레임워크를 따르고 GPT 계열의 사전 훈련된 모델에 의존한다.
*자동 평가는 우리의 프레임워크가 여전히 강력한 작업별 neural baseline에 약간 못 미친다는 것을 나타내지만, 그것은 또한 우리의 프레임워크의 주요 장점을 암시한다. 그것은 널리 휴대할 수 있고 많은 도메인에 쉽게 적응할 수 있으며 복잡한 모듈식 설계를 적은 성능 비용으로만 우회한다. 또한 사용자 중심 평가는 두 모델 사이에 유의한 차이가 없음을 시사한다.
* 사실상 가장 핵심. 모듈식 설계를 텍스트 형식의 입력으로 우회하는 간소화를 하며 성능이 떨어지지 않았다는 것.
2. From Unsupervised Pretraining to Dialogue Modeling,
2.1. TransferTransfo Framework
Relate work은 간단하게 요약했다.
(2.) 작업 지향 대화 모델링에는 도메인별로 수동으로 라벨링 한 데이터가 필요하다.
그렇기에 대형 코퍼스를 학습시킨 사전학습 데이터에 수동으로 라벨링 한 데이터를 전이 학습으로 적용시킬 수 있는가 라는 의문이 생기고
이에 대한 연구가 여러 논문에서 성과가 있었다.
(2.1.) TransferTransfo Framework가 무엇인지에 대하여 간단하게 설명한다.
3. Domain Transfer for (Task-Oriented) Dialogue Modeling
(작업 중심의) 대화 모델링을 위한 도메인 전송
3.1 Domain Adaptation and Delexicalization
도메인 적응 및 *탈어휘화
* Delexicalization : 다소 번역하기 어려운 부분이다.
오전 3:15 -> <Time>
Mr. Na -> <Name>
NLP에서는 위와 같은 작업을 말할 때 쓰는 용어라고 한다.
탈어휘화 된 단어 out-of-vocabulary(OOV)를 다루는 것은 생성된 출력을 자주 탈어휘화 시켜야 하는 작업 지향 생성에는 더 중요하다. 탈어휘화는 슬롯 값을 해당(일반) 슬롯 토큰으로 대체하고 값 독립 매개 변수를 학습할 수 있도록 합니다. 최근에는 서브워드 레벨 토큰화로 인해 언어 모델이 이제 OOV 및 도메인별 어휘를 보다 효과적으로 처리할 수 있게 되었다.
* Subword Tokenizer
3.2 Simple Text-Only Input
최근 간단한 텍스트 형식으로 NLP 작업을 posing 하면 비지도 아키텍처를 개선할 수 있다는 경험적 검증이 있었다.
예를 들어 작업 지향 대화 모델링에서 Sequicity model은 belief state에 대한 분류를 생성 문제로 본다.
이렇듯 모든 대화 모델의 파이프라인은 sequence-to-sequence 아키텍처를 기반으로 한다, 하나의 모델의 출력은 후속 반복 모델의 입력인 셈이다.
* 멀티턴을 가정하고 belief state가 저장되기 때문
해당 논문은 belief 상태와 지식기반 상태(knowledge base state)를 모두 생성자에게 간단한 텍스트 형식으로 제공하는 접근법을 따른다. 이것은 작업 지향 모델 구축의 패러다임을 단순화시킨다. 모든 새로운 정보의 소스는 간단하게 자연어로 텍스트 입력의 한 부분으로 추가될 수 있다.
3.3 Transferring Language Generation Capabilities
언어 생성 기능 전송
figure 2. 해당 논문의 최종적 아키텍처다.
Transformer 아키텍처는 fine-tuning 단계에서 새로운 (즉, 도메인별) 토큰 임베딩을 학습하는 능력을 보여준다.
이는 GPT 모델이 특별한 토큰을 통해특정 작업에 적응할 수 있다는 것을 의미한다. 입력 표현을도메인별 토큰과 함께 텍스트로 제공함으로써, 우리는 새로운 대화 하위 모듈을 훈련할 필요 없이 기성(off-the-shelf) 아키텍처를 사용하고 도메인별 입력에 적응할 수 있다.
토큰 레벨 레이어(Figure 2)는 Transformer의 Decoder에게 입력의 어떤 부분이 시스템 측 또는 사용자 측으로부터 오는지 알려준다.
그러면 해당 모델은 fine-tuning 중에 두 개의 작업 지향 특정 토큰(System과 User의 토큰)을 생성한다.
3.4 Generation Quality
생성 퀄리티
마지막으로 오랜 기간 문제 되었던 지루하고 반복적인 응답 생성 문제가 최근 연구의 초점이 되었다.
이는 새로운 샘플링 전략들로 인하여 생성 모델이 더 길고 일관된 시퀀스 출력을 생성할 수 있게 되었다. (해결)
* 언어 생성 모델을 테스트하다 보면 가끔 특정 부분에서 몇 가지의 연관된 단어가 반복되어 이상한 응답이 나오는 경우가 종종 있는데 그것을 말하는 것 같다. ex) <start> 오늘은 밥이 맛있는 것 같다. 음~ 배불러~ 음~ 배불러~ 음~ 배불러~ 음~ 배불러~....
이는 오픈 도메인 대화 모델링에 대하여도 다른 논문에서 검증되었다.
이 논문은 최근 제안된 *nucleus sampling (핵 샘플링) 절차뿐만 아니라 표준 디코딩 전략을 실험한다.
표준 탐욕 샘플링 전략(standard greedy sampling strategy)은 다음 항목을 선택합니다.
greedy sampling : 단어마다 로그 확률을 적용해 가장 높은 확률의 단어를 뽑는다.
* nucleus sampling : Top P sampling이라고도 부른다. Top K sampling의 분포에 상관없이 고정된 k개를 샘플링하여 엉뚱한 단어가 나올 수도 있는 문제를 보완하여 누적 분포를 계산하여 누적 분포 함수가 P값을 초과할 경우 샘플링하여 분포에 따라 유연하게 선택 가능성을 조절하는 샘플링 방법이다.
반면 nucleus sampling은 p 번째 % 에서 나오는 단어로만 제한됨으로 선택된 단어들의 확률은 재조정되고 이 부분 집합에서 시퀀스가 샘플링된다.
해당 논문은 성능을 손상시키지 않고 greedy sampling 대신 nucleus smpling에 의존하면서도 더 다양하고 의미적으로 풍부한 응답을 생성할 수 있는 대규모 pre-trained model의 능력을 조사했다.
4. Fine-Tuning GPT on MultiWOZ
GPT 생성에 대한 Fine tuning의 전이 능력을 평가하기 위해 대화 작업과 도메인을 제약하고 집중해야 했고,
그러기 위해 다중 도메인 MultiWOZ dataset을 이용했다.
MultiWOZ는 7개의 도메인과 10438개의 대화로 구성되어있고 인간과 인간의 상호작용을 통해 모인 대화인 만큼 자연스러운 대화 데이터이다.
하지만 대화 데이터에는 예약 ID나 전화번호 같은 도메인별 어휘를 기반으로 하기에, 이는 데이터베이스에 전적으로 의존적이기에 삭제되어야 한다.
*개인적으로 좋아했던 "이루다"서비스 같은 경우가 이러한 데이터베이스 의존적 데이터를 정제하지 못하여 문제가 있었다.
예를 들면 이름 같은 개인정보 말이다.
Natural Language as (the Only) Input
GPT는 텍스트 입력으로만 작동한다.
이것은 beilef state와 database state가 숫자 형식으로 인코딩 되는 표준 작업 지향 대화 아키텍처와 반대된다.
예를 들면 database state는 일반적으로 현재 상태에서 사용 가능한 엔티티들을 나타내는 n-bin 인코딩으로 정의된다.
따라서 beilef state와 지식 기반 표현을 간단한 텍스트 표현으로 변환한다.
belife state는 다음과 같은 형태이다.
그리고 database 표현은 다음과 같이 제공된다.
본 연구에서는 지식 기반상태를 자연어 형식으로 변환하고 이 두 가지 정보(belief, database)가 전체 대화 맥락을 형성하게 한다.
대화에 참여하는 두 당사자를 위해 새로운 토큰 임베딩을 추가하여 관심 계층에게 컨텍스트의 일부가 사용자로부터 오고 시스템과 관련된 부분이 무엇인지 알려준다.
*figure 2를 보면 굳이 글을 읽지 않아도 직관적인 이해가 가능하다.
Training Details
fine-tuning 가능한 checkpoint를 제공하는 GPT와 GPT-2 아키텍처의 오픈소스를 사용했다.
해당 연구에서 language model loss에 대한 가중치를 응답에 대한 prediction 가중치보다 2배 높게 설정했다.
파라미터 설정은 아래와 같으며 *grid search를 기반으로 선택되었다.
- batch size : 24
- learning rate : 1e-5
- candidates per sequence : 2
* grid search : 파라미터 선택 방법론 중 하나입니다. 특정 범위 값을 grid로 나누어 모든 경우에서의 성능을 확인하여 선택하는 방법
5. Results and Analysis
해당 연구의 평가 과제는 dialogue-context-to-text 작업이다.
주요 평가는 두개의 모델 사이의 비교를 기반으로 한다.
베이스 라인은 oracle belief state를 가진 뉴럴 응답 생성 모델
(4.)에서 제안되고 figure 2에서 제시한 모델
해당 연구는 pretrained GPT model, original GPT model을 테스트하며 2개의 GPT2 모델인 small (GPT2), medium GPT2-M)를 참조했다.
5.1. Evaluation with Automatic Measures
3가지 표준 자동평가 방법으로 점수를 냈다.
1. 시스템이 적절한 엔티티(정보)를 제공했는가
2. 요청된 모든 속성에 응답했는지 성공률
3. 유창성 (BLEU 점수로 측정)
*BLEU Score 기계의 응답과 사람의 응답의 유사도를 비교하는 방법이다.
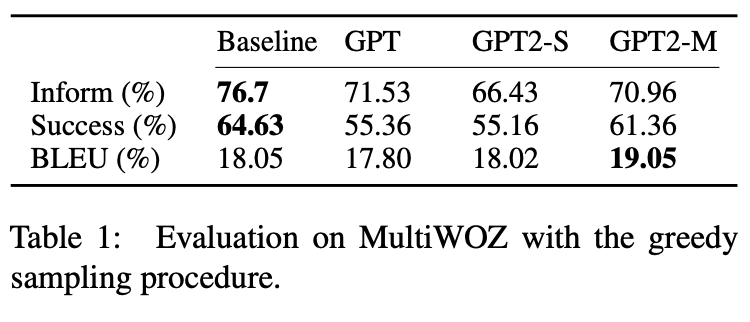
첫 번째는 MultiWOZ에서 세 가지 버전의 GPT를 미세 조정하고 greedy sampling을 사용하여 평가했다.
결과는 Table 1에 요약되어있다.
이것은 Baseline이 Task(Inform, Success) 관련에서는높은 점수를 받았지만
BLEU(유창성)은 GPT2-M에서 가장 높은 점수를 기록했다.
GPT기반 방법의 성능은 낮았지만 해당 논문의 실험은 모델 설계의 단순성에 주목한다.
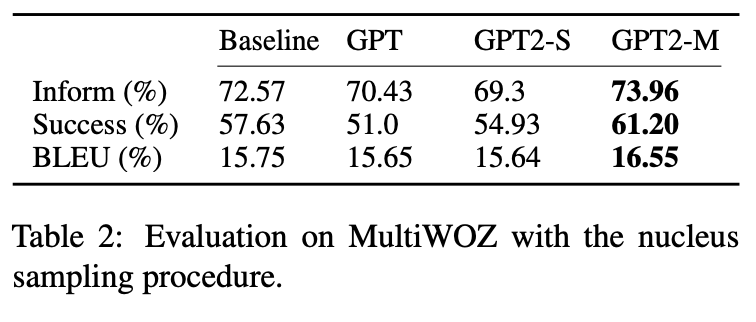
따라서 표 2의 nucleus sampling 방법으로도 결과를 보고한다.
위 결과를 보면 점수를 통해 올바른 샘플링 방법을 선택하는 게 중요하다는 것을 확인할 수 있다.
GPT2모델은 Inform과 Success 점수를 향상시킨다.
이때 모든 모델에서 BLUE 점수가 일관되게 하락하는데 nucleus sampling를 사용하면 결과의 가변성이 증가하기 때문이다.
또한 이는 도메인별 토큰을 생성할 확률을 감소시킬 수 있다.
*즉 전체적으로 점수가 낮아지긴 한다는 것이다.
5.2. Human Evaluation
영어를 모국어로 사용하는 *사람들은 Baseline, GPT, GPT2-M 및 대화에서 one-turn응답을 제시하면 이진 선호도를 평가하도록 요청받았다.
사람들은 서로 다른 모델이 생성한 2개의 응답을 받아서 어떤 응답을 선호하는지 선택했다.
*해당 논문에서는 평가자들을 Turker라고 칭한다.
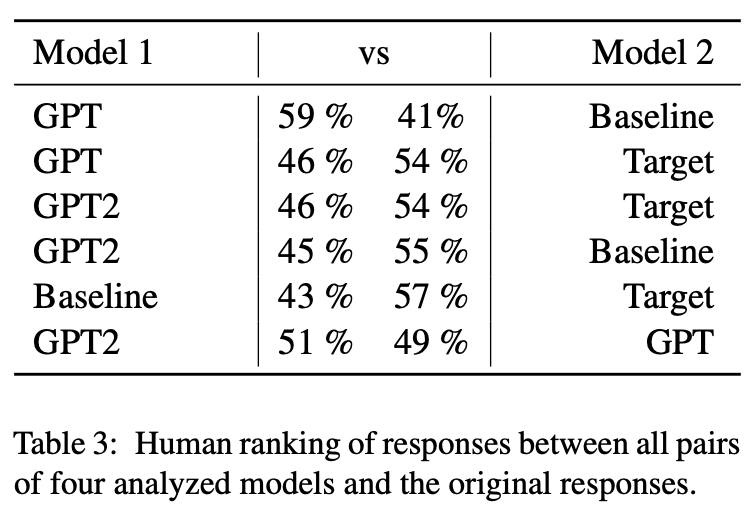
결과는 Table 3에 요약되어있다.
GPT에서 생성된 출력이 baseline보다 강하게 선호되었고, GPT2 모델에서는 그 반대였다.
이렇게 결론을 낼 수 없는 결과는 이후 연구에서 추가 분석을 요구하고 baseline과 GPT기반 모델을 비교할 때품질에 상당한 차이가 없음을 보여준다.
6. Conclusion
본 논문에서는 작업 지향 대화를 모델링하기 위해 pretrained 생성 모델을 이용했다.
필요한 정보를 텍스트로 인코딩할 수 있는 fine-tuning절차의 단순성은 제한된 도메인과 도메인별 어휘에 빠르게 적응 가능하다.