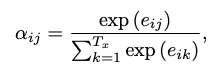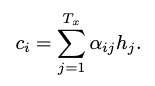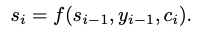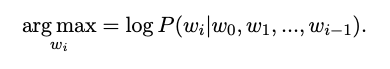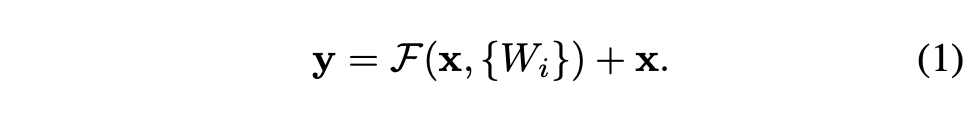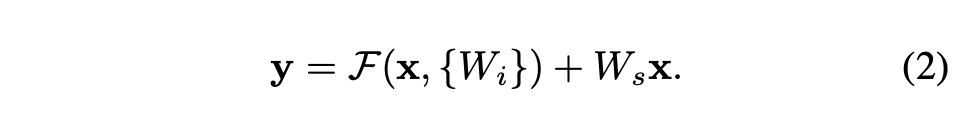발화 데이터를 Separate Speech를 하면 Single Speaker일 경우 denoising 해주는 모델이 있고.
Multi Speaker일 경우 발화자A, 발화자B 이런식으로 분리된 음성으로 나누어주는 모델이 있었다.
ST: Speech Translation & Machine Translation
흔히 아는 음성 번역이다.
VC: Voice Conversion
목소리를 변환한 음성을 만들어주는 모델이다.
SVS: Singing Voice Synthesis
노래하는 목소리 생성 모델이다.
Docker 실행
도커에서 성공적으로 ESPnet을 돌렸다. 튜토리얼대로 똑같이하면 아무런 문제없이 잘 돌아갔다.
튜토리얼에서는 Demo 버전을 웹을 이용해서 테스트 할수있는 여러 환경을 구성하고있다.
기존에 Docker compose를 이용해 메인 컨테이너랑 묶어 해당 모델을 사용하려고 했으나 당장의 프로토타이핑 스탭에서 Docker를 사용하지 않기로 했다.
여담
우선 해당 프로젝트는 1인개발 프로젝트여서 다중환경을 지원할 필요성이 크게없다.
(하지만 나중에는 Docker에 올려야한다는 생각정도는 가지고있다.)
다만 만드는 과정에서 Docker환경에 맞춰서 개발하기 좀 고달프다. 그이유는 음성 인식 부분을 마이크 입력이 아닌 웹규격이나 소켓 데이터 스트림으로 구현해야한다는 점 때문이다. 그렇기에 이러한 부분에 대해서 고민할 부분을 조금 뒤로 미루기위해 여러 시도와 실험 끝에 잠깐 Docker 사용을 놔주기로했다.
Test
Espnet에서 가장 유용하다고 생각한 부분은 역시 TTS모델을 다양하게 사용할 수 있다는 점이였다.
그중 테스트해본 여러 모델들중 괜찮다는 생각이 든 모델들을 정리해보겠다.
Espnet model zoo를 사용하면 다음과 같이 매우 간단하게 huggingface에서 모델을 이용해서 음원을 만들수있다.
속도는 약간 아쉬운 느낌이긴 하지만 아쉬운건 CPU기준이고 GPU로 한다면 매우 높은 성능이 나올거라고 기대하고있다.
언어 모델을 이용하여 Agent를 설정된 집단과 환경에서 인간과 유사하게 행동할 수 있도록 하는 simulation을 구현한 연구에 대한 논문이다.
Agent는 큰 언어모델(chatgpt)에 Agent의 경험을 기억할 수 있고,
그 기억을 높은 수준으로 반영하여 반응을 생성하며,
그 데이터들을 동적으로 행동을 계획하기 위해 불러올 수 있다.
Keywords
Human-AI Interaction
Agents
Generative AI
Large language models
Introduction
인공 사회를 만드는데는 “The Sims”(게임)에서 영감을 받아서 가상 환경을 설계했다.
환경에 던져진 Agent들은 과거의 경험과 괴리가 없도록 일관적으로 행동했고,
어떻게 어려운 대인관계의 상황을 해결하는지를 학습했으며
사회 과학의 이론을 테스트 했으며
이론과 사용성 테스트를 위해 위한인간의 행동 프로세스를 만들었다.
하지만 인간행동은 방대하며 복잡하기에, 큰 언어모델로 single time point에서 인간행동 시뮬레이션이 가능하더라도, 긴 텀동안 일관성 있는 agent가 새로운 상호작용, 갈등, 이벤트로 인해 끊임없이 늘어나는 정보를 기억하는 아키택처가 더 적합하다.
3. Generative Agent Behavior And Interaction
(작성중)
Inter-Agent Communication
User Controls
Information Diffusion
Relationship memory
Coordination
4. Generative Agent Architecture
generative agent는 현재 상태를 가지고 가지고 있고, 과거의 경험을 입력으로 받으며 행동을 출력해낸다. 해당 구조는 language모델의 상태와 정보등을 합성하여 출력을 만든다. 이러한 아키텍처는 agent의 출력이 과거 경험에 기반하게 하고, 중요한 추론을 만들어내며, 긴 텀동안의 통일성을 유지시켜줄 수 있도록 제어하는 역할을 한다.
4.1 Memory and Retrieval
Challenge
Agent가 추론을 하게 하기 위해서 과거 경험 데이터 뿐만 아니라 현재 데이터도 넣어줘야 할텐데 어떻게 prompt를 설계해야할까? 제한된 context window 어떻게 이 많은 요소를 넣어야 하는가.
Approach
agent의 정보를 메모리스트림에 포괄적으로 저장하여 이후 관찰하기 쉽게 한다. 추가로 저장되는 정보는 다음과 같다.
natural language description
timestamp / most recent access timestamp
Recency
최신 정보에 높은 점수를 부여했다. 점수는 정보에 생성, 접근한 timestamp를 이용했으며, 시간에 따른 decay(0.99)를 부여했다. decay는 exponential decay function을 이용.
Importance
중요도를 평가하는 다양한 방법이 있겠지만, 해당 논문에서는 언어모델을 사용하여 사진과 같은 프롬프트로 중요도를 데이터 스트림에 저장하게 했다.
Relevance
현재 상황과 관련있는 정보에 높은 점수를 부여했다. 예를들면 화학시험에 대한 논의를 하는 상황일때, “오늘 먹은 아침”보다 “학교에서 공부한 것”이 더 높은 점수를 얻는 것이다. 해당 논문에서는 데이터셋을 벡터화하여 cosine 유사도로 관련성을 평가했다.
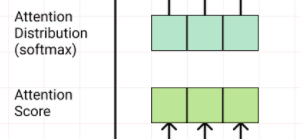
Combination
각 부분에 weighted combination을 하여 계산 하게 했으며, 해당논문에선 weight를 모두 1로 두어서 그림과 같은 형태가 된다.
4.2 Reflection
Challenge
날것의 관찰 데이터만 가진 agent는 일반화하기와, 관련성 만들기를 하기에 혼란을 겪는다. 그렇기에 더 바람직한 응답을 하기 위해 agent는 시간이 지남에 따라 더 높은 수준의 reflection을 만들어 내는 memory의 일반화가 요구된다.
Approach
reflection이라고 부르는 두번째 타입의 메모리를 만듬. 이는 agent가 생성하는 더 높은 수준의 추상인 생각이다. 이전의 이벤트에서 쌓인 importance score의 합계가 임계값을 넘을 경우 reflection을 수행한다. 해당 논문의 agent들은 2~3회 reflection을 수행했다.
논문의 내용이 단번에 이해하기 어려웠어서 간단하게 설명하면 다음 과정을 거친다.
최근 쌓인 기억들의 중요도합이 임계치를 넘었을 경우 발동
최근 100개의 기억을 입력으로 넣어서 해당 기억으로 대답이 가능한 매우 높은 수준의 질문을 3개 생성해달라고 언어모델에 입력.
생성된 질문을 이용해서 나온 3개의 질문을 입력으로 추론 할 수 있는 높은 수준의 통찰 5가지를 생성하고, 어떤 문장에서 얻은 통찰인지도 같이 출력해 달라고 언어모델에 입력.
해당 통찰이 담긴 문장을 통해 Reflection Tree 가 생성됨. / 해당 통찰이 담긴 문장은 다시 Reflection이벤트가 있을때 검색될 수 있다.
(2)
(3)
4.3 Planning and Reacting
Challenge
계획성, 일관되고 신뢰할만한 행동을 보이기 위해는 계획이 필요하다. 계획 없이는 Agent가 점심을 먹는다고 가정할때 12시에 저녁먹고 12:30에 또먹고 1시에 또먹고 하는 일이 일어날 수 있다.
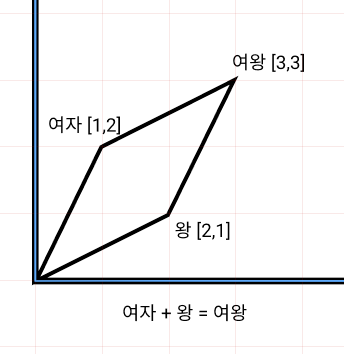
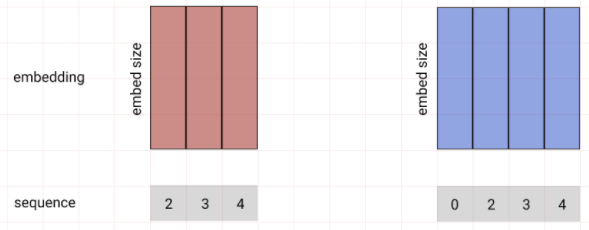
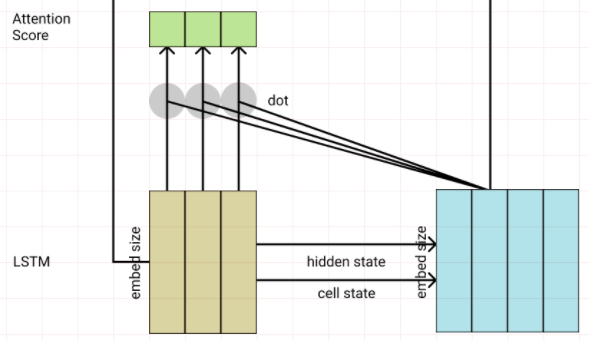
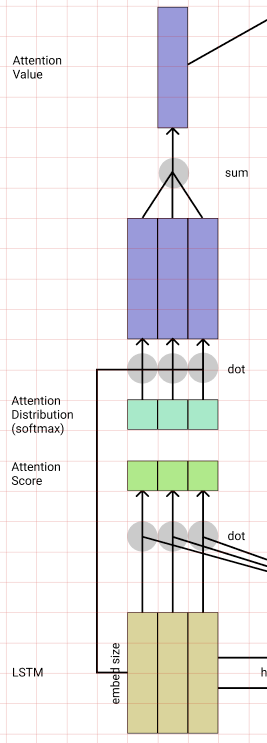
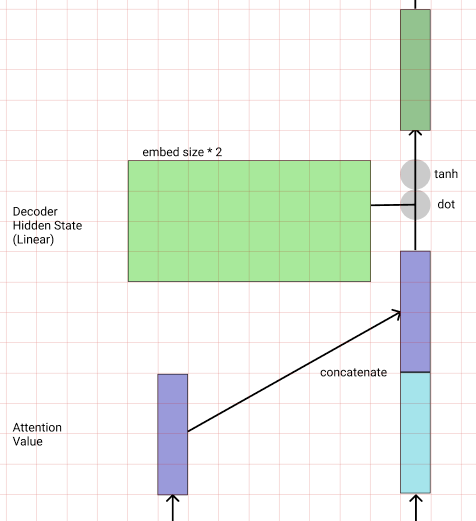
단어를 생성하는 방법으로 의미 해석 레이어를 달아 어떤 단어를 선택할지 결정하는 Linear레이어와 Softmax로 단어의 Sequence를 뽑게 만들었다.
# wy (output)
wy = nn.Linear(embed_size, tar_n_vocab) # (embed_size, word_cnt)
# softmax (nll_loss로 연산하기 위해 log_softmax)
x = F.log_softmax(x, dim=2)
Teacher Forcing
일반적으로 교사강요 라고 해석하는 것 같다.
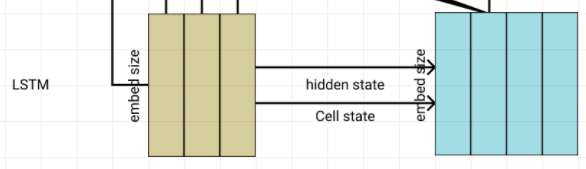
Seq2seq 모델에서 RNN에서 나온 출력을 다음 step의 입력으로 넣어주는 구조로 출력 리스트를 만들어 낸다. (추론)
이러한 모델을 학습시킬때 step중간에서 원하는 출력이 나오지 않으면 다음 step에 원하는 입력을 주지 못할 것이고 해당 시점 이후로 모든 값이 틀려 버릴 수 있다.
이러한 문제 때문에 RNN의 모든 step에서 입력으로 정해진 값만 입력으로 넣어주는 방법을 교사강요라고 한다.
하지만 이방법을 과하게 이용할 경우, 테스트시 사용될 방식인 추론과 교사강요를 통한 학습의 생성 방식의 차이로Exposure Bias Problem (노출 편향) 문제가 발생한다.
이게 어떤 문제인지 조금 상상해보자면 Embedding된 단어의 의미를 이용하여 다음 출력에 대한 추론을 해야하고 이는 목표출력과 Embedding 거리와 가까운 출력을 낼 수 있을 것 같은데, 그때 이 출력이 입력으로 들어가여 학습하면 해당 주변의 단어에 대하여 유연한 추론이 가능 할 것이라고 생각된다. 그렇기에 Teacher Forcing을 이용하면 이러한 유연성을 학습할 수 없다는 문제가 있지 않을까 생각해봤다.
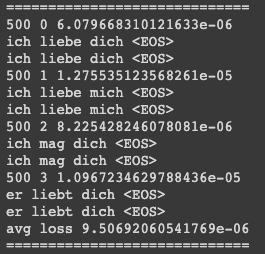
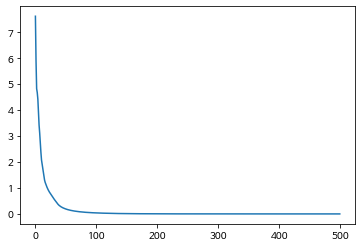
아무튼 이러한 이슈 때문에 랜덤확률로 Teacher Forcing사용을 조절하는 방법을 사용하거나, 정확성이 부족한 초반에만 사용하는 방식등이 있는 것 같다.
하지만 이러한 노출편향 문제가 사실 별로 큰 영향을 끼치지는 않는다는 논문이 이후 발표되어 있긴 하다.
해당 논문을 원활히 읽기 위해서는 아래의 논문에 대하여 어느 정도 이해가 있다면 편하게 읽을 수 있다.
seq2seq, Transformer, GPT2, TransferTransfo
Abstract
문제점
데이터 부족은 여러 영역에서 task-oriented dialogue system의 빠른 개발을 오랜 시간 방해하는 장기적이고 중대한 과제이다.
* task-oriented dialogue system - 작업(업무) 지향적 대화형 시스템
작업 지향적 대화형 모델 학습을 위한 문법, 구문, 대화 추론, 의사 결정, 언어 생성 작업들을 터무니없이 적은 데이터로 학습할 것으로 예상된다.
목적
해당 논문에서 최근 진행된 언어 모델링 사전 학습과 전이 학습이 이 문제를 해결할 가능성을 보여주려고 한다.
해당 논문은 텍스트 입력만으로 작동하는 작업 지향적 대화형 모델을 제안한다. 이는 명시적 정책(모델 학습을 위한 것들)들과 언어 생성 모듈을 효과적으로 우회한다.
결과
TransferTransfo 프레임워크(Wolf et al., 2019)와 생성 모델 사전 학습(Radford et al., 2019)을 기반으로 ImageNet데이터 세트에서 MultiWOZ의 복잡한 다중 도메인 작업 지향 대화에 대한 접근법을 검증한다.
* MultiWOZ: Wizards of Oz(WOZ)란 크라우드 소싱 환경에서 두 명의 임의의 참여자가 “사용자”와 “에이전트”의 역할을 나누어 대화를 나누며 데이터를 생성하는 형태를 의미한다. MultiWOZ는 호텔, 택시, 레스토랑, 기차 등을 포함하는 7개 영역에서의 예약과 관련된 약 1만여 개의 대화 세션들로 구성된 데이터이다.
우리의 *자동 평가와 인간 평가는 제안된 모델이 강력한 작업별 neural baseline과 동등하다는 것을 보여준다. 장기적으로, 우리의 접근 방식은 데이터 부족 문제를 완화할 수 있고 작업 지향형 대화 에이전트 구성을 서포트할 가능성이 있다.
Summery
요약보다는 공부하는 느낌으로 읽었다. 너무 쉬워서 패스하는 구문 없이 번역하는 느낌으로 꼼꼼히 정리했다.
1. Introduction
통계적 회화 체계는 2개의 메인 카테고리로 얼추 분류할 수 있다.
작업 지향적 모듈식 시스템
오픈 도메인 chit-chat 뉴럴 모델
* chit-chat : 잡담, 수다
전자는 일반적으로 언어 이해, 대화 관리 및 응답 생성과 같은 독립적으로 훈련된 구성 모듈로 구성된다.
이러한 시스템의 주된 목표는 제한적인 도메인과 작업에서 실질적인 가치가 있는 대화 에이전트를 구축함에 있어서 의미 있는 시스템 응답을 제공하는 것이다.
하지만 이러한 시스템을 위한 데이터 수집과 주석은 복잡하다. 시간적으로, 비용적으로 봤을 때 말이다.
그리고 (데이터를) 양도받기 쉽지 않다.
반면 후자인 오픈 도메인 회화 봇은 자유롭게 이용할 수 있는 주석 처리되지 않은 대량의 데이터들을 활용할 수 있다.
많은 말뭉치들(corpora)은 일반적으로 sequence-to-sequence 아키텍처를 사용하여 end-to-end 뉴럴 모델로 학습할 수 있다.
이것은 고도로 데이터 중심적이지만 이러한 시스템은 신뢰성이 낮고 의미 없는 대답을 만들어내기 쉬움으로 실제 회화 애플리케이션의 생산을 방해한다.
이렇듯 해결되지 않은 end-to-end 아키텍처의 이슈 때문에 검색 기반(retrieval-based) 모델로 초점이 이동했다.
작업 특화 애플리케이션에서 검색 기반 모델은
대규모 데이터 셋을 활용하여 좋은 영향을 준다는 장점이 잇었으며,
시스템 응답에 대한 모든 제어가 가능하지만, 높은 확률로 예측이 가능하다는 단점이 있었다.
즉 pre-existing set에 의존적이며 일반적으로 멀티 도메인에 서 부적절하다.
* 즉 검색 시스템의 응답은 대규모 데이터를 이용해 학습할 시 모든 상황에 대한 응답 제어가 가능하지만,
학습 데이터에 따라 너무 뻔한 대답이 나올 확률이 높다는 것이다.
하지만 최근 연구된 GPT, GPT2와 같이 대용량 데이터셋과 대용량 언어 모델은 생성 모델이 작업 기반 대화 애플리케이션을 지원할 수 있을 거란 질문을 다시 열어준다.
최근 연구진은 fine-tuning 된 GPT모델이 개인적인 회화 분야에서 유용할 수 있음을 보였다.
이러한 접근법은 Persona Chat dataset에서 상당한 개선을 이끌고, 회화 도메인 이서 대규모 사전 학습된 생성 모델 사용에 대한 가능성을 보였다.
* GPT pre-trained 모델을 사용하여 작업 기반 대화 애플리케이션을 만들 수 있을 것이라는 가능성 언급
위 논문에서는 일반적인 주제에 대한 대규모 말뭉치 데이터를 사전 학습한 대규모 생성 모델이 작업 지향형 대화형 애플리케이션을 지원할 수 있다는 것을 보이려고 한다.
첫째로 워드 토큰화, 다중 작업 학습, 확률적 샘플링과 같은 다양한 구성 요소를 결합하여 작업 지향 애플리케이션을 지원하는 방법에 대해 논의한다. 그런 다음 명시적 대화 관리 모듈과 도메인별 자연어 생성 모듈을 효과적으로 우회하여 텍스트 입력에서 완전히 작동하도록 모델을 조작하며, 제안된 모델은 전적으로 시퀀스 대 시퀀스 방식으로 작동하며 간단한 텍스트만 입력으로 소비한다.
* 대화 관리 모듈과 자연어 생성 모듈의 콘텐츠를 모델의 텍스트 입력으로 작동 가능하도록 우회한다는 말이다.
dialogue context to text task
Belief 상태, 데이터베이스 상태 및 이전 턴을 포함하는 전체 대화 콘텍스트는 디코더에 원시 텍스트로 제공된다.
* belief state : 대화의 진행 정보를 저장하는 상태 정도로 이해하면 된다. figure 1을 보면 쉽게 이해할 수 있다.
제안된 모델은 최근에 제안된 TransferTransfo 프레임워크를 따르고 GPT 계열의 사전 훈련된 모델에 의존한다.
*자동 평가는 우리의 프레임워크가 여전히 강력한 작업별 neural baseline에 약간 못 미친다는 것을 나타내지만, 그것은 또한 우리의 프레임워크의 주요 장점을 암시한다. 그것은 널리 휴대할 수 있고 많은 도메인에 쉽게 적응할 수 있으며 복잡한 모듈식 설계를 적은 성능 비용으로만 우회한다. 또한 사용자 중심 평가는 두 모델 사이에 유의한 차이가 없음을 시사한다.
* 사실상 가장 핵심. 모듈식 설계를 텍스트 형식의 입력으로 우회하는 간소화를 하며 성능이 떨어지지 않았다는 것.
2. From Unsupervised Pretraining to Dialogue Modeling,
2.1. TransferTransfo Framework
Relate work은 간단하게 요약했다.
(2.) 작업 지향 대화 모델링에는 도메인별로 수동으로 라벨링 한 데이터가 필요하다.
그렇기에 대형 코퍼스를 학습시킨 사전학습 데이터에 수동으로 라벨링 한 데이터를 전이 학습으로 적용시킬 수 있는가 라는 의문이 생기고
이에 대한 연구가 여러 논문에서 성과가 있었다.
(2.1.) TransferTransfo Framework가 무엇인지에 대하여 간단하게 설명한다.
3. Domain Transfer for (Task-Oriented) Dialogue Modeling
(작업 중심의) 대화 모델링을 위한 도메인 전송
3.1 Domain Adaptation and Delexicalization
도메인 적응 및 *탈어휘화
* Delexicalization : 다소 번역하기 어려운 부분이다.
오전 3:15 -> <Time>
Mr. Na -> <Name>
NLP에서는 위와 같은 작업을 말할 때 쓰는 용어라고 한다.
탈어휘화 된 단어 out-of-vocabulary(OOV)를 다루는 것은 생성된 출력을 자주 탈어휘화 시켜야 하는 작업 지향 생성에는 더 중요하다. 탈어휘화는 슬롯 값을 해당(일반) 슬롯 토큰으로 대체하고 값 독립 매개 변수를 학습할 수 있도록 합니다. 최근에는 서브워드 레벨 토큰화로 인해 언어 모델이 이제 OOV 및 도메인별 어휘를 보다 효과적으로 처리할 수 있게 되었다.
* Subword Tokenizer
3.2 Simple Text-Only Input
최근 간단한 텍스트 형식으로 NLP 작업을 posing 하면 비지도 아키텍처를 개선할 수 있다는 경험적 검증이 있었다.
예를 들어 작업 지향 대화 모델링에서 Sequicity model은 belief state에 대한 분류를 생성 문제로 본다.
이렇듯 모든 대화 모델의 파이프라인은 sequence-to-sequence 아키텍처를 기반으로 한다, 하나의 모델의 출력은 후속 반복 모델의 입력인 셈이다.
* 멀티턴을 가정하고 belief state가 저장되기 때문
해당 논문은 belief 상태와 지식기반 상태(knowledge base state)를 모두 생성자에게 간단한 텍스트 형식으로 제공하는 접근법을 따른다. 이것은 작업 지향 모델 구축의 패러다임을 단순화시킨다. 모든 새로운 정보의 소스는 간단하게 자연어로 텍스트 입력의 한 부분으로 추가될 수 있다.
3.3 Transferring Language Generation Capabilities
언어 생성 기능 전송
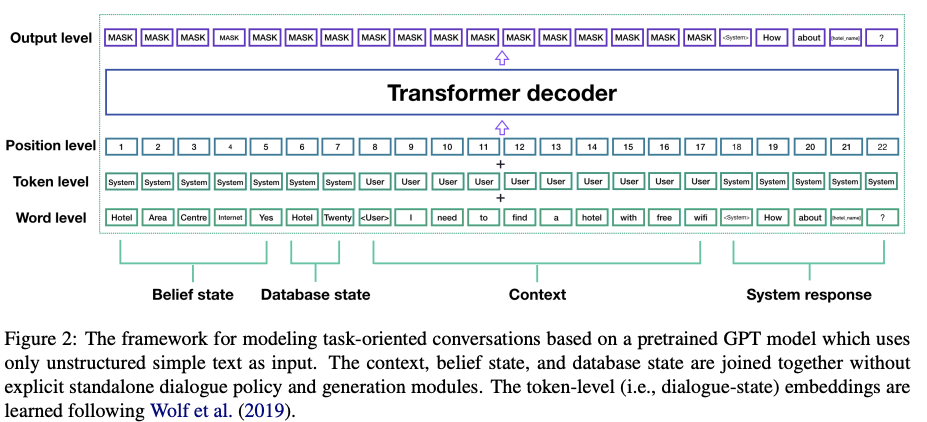
figure 2. 해당 논문의 최종적 아키텍처다.
Transformer 아키텍처는 fine-tuning 단계에서 새로운 (즉, 도메인별) 토큰 임베딩을 학습하는 능력을 보여준다.
이는 GPT 모델이 특별한 토큰을 통해특정 작업에 적응할 수 있다는 것을 의미한다. 입력 표현을도메인별 토큰과 함께 텍스트로 제공함으로써, 우리는 새로운 대화 하위 모듈을 훈련할 필요 없이 기성(off-the-shelf) 아키텍처를 사용하고 도메인별 입력에 적응할 수 있다.
토큰 레벨 레이어(Figure 2)는 Transformer의 Decoder에게 입력의 어떤 부분이 시스템 측 또는 사용자 측으로부터 오는지 알려준다.
그러면 해당 모델은 fine-tuning 중에 두 개의 작업 지향 특정 토큰(System과 User의 토큰)을 생성한다.
3.4 Generation Quality
생성 퀄리티
마지막으로 오랜 기간 문제 되었던 지루하고 반복적인 응답 생성 문제가 최근 연구의 초점이 되었다.
이는 새로운 샘플링 전략들로 인하여 생성 모델이 더 길고 일관된 시퀀스 출력을 생성할 수 있게 되었다. (해결)
* 언어 생성 모델을 테스트하다 보면 가끔 특정 부분에서 몇 가지의 연관된 단어가 반복되어 이상한 응답이 나오는 경우가 종종 있는데 그것을 말하는 것 같다. ex) <start> 오늘은 밥이 맛있는 것 같다. 음~ 배불러~ 음~ 배불러~ 음~ 배불러~ 음~ 배불러~....
이는 오픈 도메인 대화 모델링에 대하여도 다른 논문에서 검증되었다.
이 논문은 최근 제안된 *nucleus sampling (핵 샘플링) 절차뿐만 아니라 표준 디코딩 전략을 실험한다.
표준 탐욕 샘플링 전략(standard greedy sampling strategy)은 다음 항목을 선택합니다.
greedy sampling : 단어마다 로그 확률을 적용해 가장 높은 확률의 단어를 뽑는다.
* nucleus sampling : Top P sampling이라고도 부른다. Top K sampling의 분포에 상관없이 고정된 k개를 샘플링하여 엉뚱한 단어가 나올 수도 있는 문제를 보완하여 누적 분포를 계산하여 누적 분포 함수가 P값을 초과할 경우 샘플링하여 분포에 따라 유연하게 선택 가능성을 조절하는 샘플링 방법이다.
반면 nucleus sampling은 p 번째 % 에서 나오는 단어로만 제한됨으로 선택된 단어들의 확률은 재조정되고 이 부분 집합에서 시퀀스가 샘플링된다.
해당 논문은 성능을 손상시키지 않고 greedy sampling 대신 nucleus smpling에 의존하면서도 더 다양하고 의미적으로 풍부한 응답을 생성할 수 있는 대규모 pre-trained model의 능력을 조사했다.
4. Fine-Tuning GPT on MultiWOZ
GPT 생성에 대한 Fine tuning의 전이 능력을 평가하기 위해 대화 작업과 도메인을 제약하고 집중해야 했고,
그러기 위해 다중 도메인 MultiWOZ dataset을 이용했다.
MultiWOZ는 7개의 도메인과 10438개의 대화로 구성되어있고 인간과 인간의 상호작용을 통해 모인 대화인 만큼 자연스러운 대화 데이터이다.
하지만 대화 데이터에는 예약 ID나 전화번호 같은 도메인별 어휘를 기반으로 하기에, 이는 데이터베이스에 전적으로 의존적이기에 삭제되어야 한다.
*개인적으로 좋아했던 "이루다"서비스 같은 경우가 이러한 데이터베이스 의존적 데이터를 정제하지 못하여 문제가 있었다.
예를 들면 이름 같은 개인정보 말이다.
Natural Language as (the Only) Input
GPT는 텍스트 입력으로만 작동한다.
이것은 beilef state와 database state가 숫자 형식으로 인코딩 되는 표준 작업 지향 대화 아키텍처와 반대된다.
예를 들면 database state는 일반적으로 현재 상태에서 사용 가능한 엔티티들을 나타내는 n-bin 인코딩으로 정의된다.
따라서 beilef state와 지식 기반 표현을 간단한 텍스트 표현으로 변환한다.
belife state는 다음과 같은 형태이다.
그리고 database 표현은 다음과 같이 제공된다.
본 연구에서는 지식 기반상태를 자연어 형식으로 변환하고 이 두 가지 정보(belief, database)가 전체 대화 맥락을 형성하게 한다.
대화에 참여하는 두 당사자를 위해 새로운 토큰 임베딩을 추가하여 관심 계층에게 컨텍스트의 일부가 사용자로부터 오고 시스템과 관련된 부분이 무엇인지 알려준다.
*figure 2를 보면 굳이 글을 읽지 않아도 직관적인 이해가 가능하다.
Training Details
fine-tuning 가능한 checkpoint를 제공하는 GPT와 GPT-2 아키텍처의 오픈소스를 사용했다.
해당 연구에서 language model loss에 대한 가중치를 응답에 대한 prediction 가중치보다 2배 높게 설정했다.
파라미터 설정은 아래와 같으며 *grid search를 기반으로 선택되었다.
- batch size : 24
- learning rate : 1e-5
- candidates per sequence : 2
* grid search : 파라미터 선택 방법론 중 하나입니다. 특정 범위 값을 grid로 나누어 모든 경우에서의 성능을 확인하여 선택하는 방법
5. Results and Analysis
해당 연구의 평가 과제는 dialogue-context-to-text 작업이다.
주요 평가는 두개의 모델 사이의 비교를 기반으로 한다.
베이스 라인은 oracle belief state를 가진 뉴럴 응답 생성 모델
(4.)에서 제안되고 figure 2에서 제시한 모델
해당 연구는 pretrained GPT model, original GPT model을 테스트하며 2개의 GPT2 모델인 small (GPT2), medium GPT2-M)를 참조했다.
5.1. Evaluation with Automatic Measures
3가지 표준 자동평가 방법으로 점수를 냈다.
1. 시스템이 적절한 엔티티(정보)를 제공했는가
2. 요청된 모든 속성에 응답했는지 성공률
3. 유창성 (BLEU 점수로 측정)
*BLEU Score 기계의 응답과 사람의 응답의 유사도를 비교하는 방법이다.
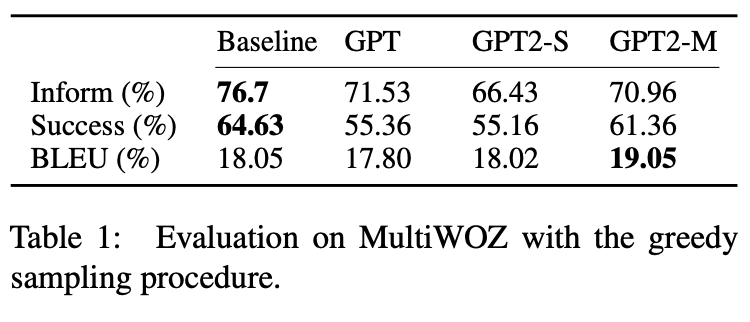
첫 번째는 MultiWOZ에서 세 가지 버전의 GPT를 미세 조정하고 greedy sampling을 사용하여 평가했다.
결과는 Table 1에 요약되어있다.
이것은 Baseline이 Task(Inform, Success) 관련에서는높은 점수를 받았지만
BLEU(유창성)은 GPT2-M에서 가장 높은 점수를 기록했다.
GPT기반 방법의 성능은 낮았지만 해당 논문의 실험은 모델 설계의 단순성에 주목한다.
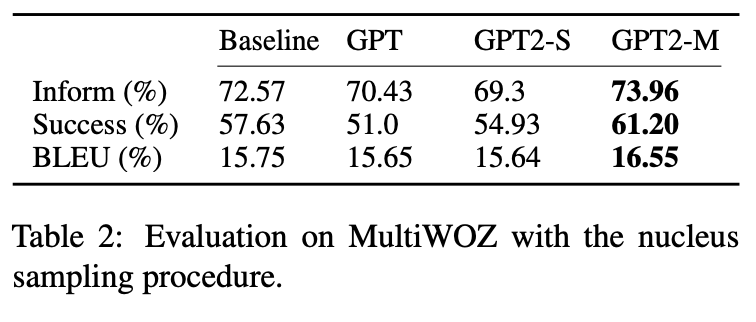
따라서 표 2의 nucleus sampling 방법으로도 결과를 보고한다.
위 결과를 보면 점수를 통해 올바른 샘플링 방법을 선택하는 게 중요하다는 것을 확인할 수 있다.
GPT2모델은 Inform과 Success 점수를 향상시킨다.
이때 모든 모델에서 BLUE 점수가 일관되게 하락하는데 nucleus sampling를 사용하면 결과의 가변성이 증가하기 때문이다.
또한 이는 도메인별 토큰을 생성할 확률을 감소시킬 수 있다.
*즉 전체적으로 점수가 낮아지긴 한다는 것이다.
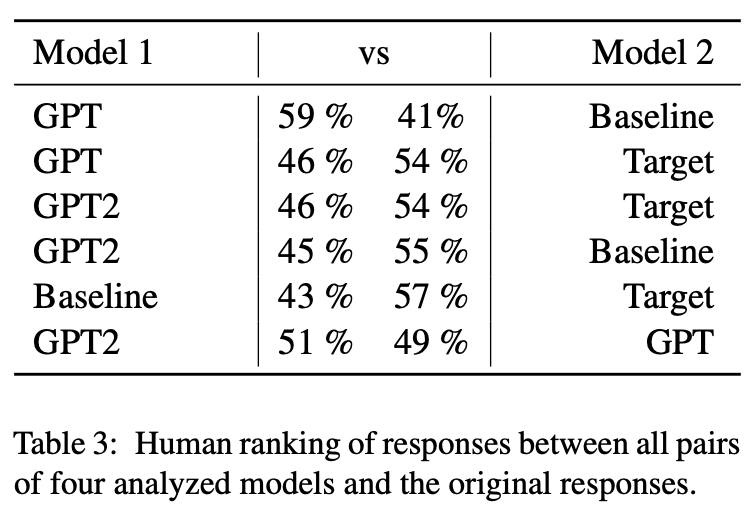
5.2. Human Evaluation
영어를 모국어로 사용하는 *사람들은 Baseline, GPT, GPT2-M 및 대화에서 one-turn응답을 제시하면 이진 선호도를 평가하도록 요청받았다.
사람들은 서로 다른 모델이 생성한 2개의 응답을 받아서 어떤 응답을 선호하는지 선택했다.
*해당 논문에서는 평가자들을 Turker라고 칭한다.
결과는 Table 3에 요약되어있다.
GPT에서 생성된 출력이 baseline보다 강하게 선호되었고, GPT2 모델에서는 그 반대였다.
이렇게 결론을 낼 수 없는 결과는 이후 연구에서 추가 분석을 요구하고 baseline과 GPT기반 모델을 비교할 때품질에 상당한 차이가 없음을 보여준다.
6. Conclusion
본 논문에서는 작업 지향 대화를 모델링하기 위해 pretrained 생성 모델을 이용했다.
필요한 정보를 텍스트로 인코딩할 수 있는 fine-tuning절차의 단순성은 제한된 도메인과 도메인별 어휘에 빠르게 적응 가능하다.
-이전의 모델들보다 더 깊은 모델을 학습하기 위한 residual learning framework (잔차 학습 프레임워크)를 제안한다.
- 해당 모델은레이어의 입력을 참조하여레이어를 잔차 학습 함수로재구성한다.
- 해당 논문은 residual network가쉽게 optimize가 되며, 상당히깊은 모델에서 정확도를 얻는경험적인 증거를 제공한다.
내용
- ImageNet dataset에서 VGG net보다 5배 더 깊지만 여전히 복잡도가 낮은 최대152 레이어 깊이의 residual network를 평가했다.
- 해당 논문은 CIFAR-10을 100개와 1000개 레이어로 분석한 내용을 담았다.
결과
- test set에서 3.57%의 에러율로 ILSVRC 2015 분류 대회에서 1위를 달성했다.
- 이외 COCO와 ImageNet에서 좋은 성과를 거두었다.
Summary
최근 연구결과들에서convolutional neural network는 deep 하게 쌓을수록 결과가 좋아서 이미지 분류에서 많이 사용되고 있으며 모델의 깊이가 매우 중요함을 시사한다.
Is learning better networks as easy as stacking more layers?
"그렇다면 레이어를 많이 쌓을수록 더 괜찮은 모델을 학습할 수 있을까?"라는의문을 가질 수 있다.
해당 질문에 대하여 대답하는 데에는 Vanishing gradients, Exploding gradients 때문이라고 생각할 수 도 있었지만,
해당 문제들은 Normalized Initialization와 Intermediate Normalization Layers에 의하여 해결되었다.
(Intermediate Normalization Layers는 Batch Normalization같은 것을 말하는 것)
깊은 게 쌓은 모델은 수렴을 시작할 때 성능 저하(degradation problem)를 보였고 모델 깊이가 증가할수록 정확도는 빠르게 떨어졌다.
기대와 다르게 이러한 성능저하는 Overfitting으로 야기된 것이 아니었다.
위의 실험으로 이를 증명했다. Figure 1을 보면 레이어를 56개 쌓은 모델과 20개를 쌓은 모델로 CIFAR10을 학습한다.
56개 쌓은 모델은 train set과 test set에서 모두 20개 쌓은 모델보다 낮은 성능을 보였다.
(Overfitting이 문제였다면 적어도 training set에서는 낮은 에러를 보여야 하지만 그렇지 않다.)
이러한 학습정확도의 저하(degradation)는 모든 시스템을 비슷하게 최적화 하기가 어려움을 보여준다.
깊은 모델을 구성하는 해결책으로는identity를 매핑하는 레이어를 추가하고이외의 레이어는 학습된 하위 모델을 복사하는 방법이 있었다.
하지만 해당방법이 실험을 통해 좋은 성능을 내진 못했으며, 해당 방법보다 더 동등하거나 더 좋은 방법을 찾지 못했다.
그렇기에 해당 논문에서deep residual learning이라는 방법을 도입했다.
각 쌓여진 레이어들이 기본 매핑으로 fit 되길 바라는 것이 아닌잔차매핑에 fit 되도록 했다.
기본매핑을 H(x)로 표시할 때, 우리는 비선형 매핑인 F(x) = H(x) - x를 제시한다. 그리고 이를 전개하면H(x) = F(x) + x가 된다.
이는 참조되지 않은 기본매핑을 fit 시키는 것보다 잔차 매핑(residual mapping)을 fit 시키기가 더 쉽다는 가정을 기반으로 한다.
To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
극단적으로 identity mapping이 optimal 하면 잔차를 0으로 만드는 것이 비선형 레이어로 identity mapping을 fit 하는 것보다 쉬울 것이다.
즉 F(x) = 0 이 되도록 학습하는 것이 더 최적화하기에 쉬운 방법이라는 것이다.
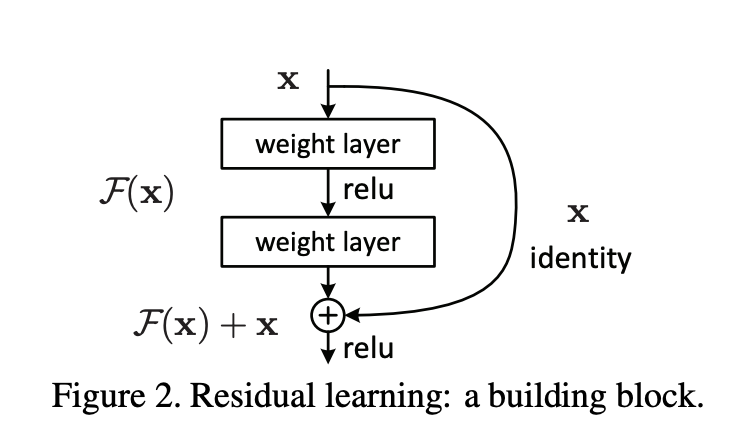
F(x) + x는 "shortcut connectons"로 실현 가능하다. shortcut connectons는 한 개 이상의 레이어를 skip 하는 것이다.
위의 경우 간단한 identity mapping을 수행하며 이것의 출력과 쌓인 레이어의 출력이 더해진다.
Identity shortcut connections 은 추가적인 파라미터와 복잡한 계산이 필요하지 않으며, 위 모델은 여전히 end-to-end로 SGD를 이용한 backpropagation이 가능하며 기본 라이브러리로 쉽게 구현할 수 있다.
위 논문에서 2가지를 보여주려고 한다.
1) deep residual net은 쉽게 optimize 되지만 plain은 deep 해질수록 높은 에러를 보이는 것
2) deep residual net은 쉽고 즐겁게(?) 레이어가 깊어질수록 이전 모델들에 비하여 높은 정확도를 얻어내는 것
Residual Learning
위와 마찬가지로 H(x)를 근사 시키는 것보다 이항 하여 F(x)를 근사 시키는 것이 학습에 있어 더 유리하다는 내용이다.
Identity Mapping by shortcut
식은 대강 이런식으로 생겼다
Fig.2에서의 모델로 재구성하면 F = W2σ(W1x) 이런 모양이 된다. 여기서는 표기를 위해 bias를 생략했다고 하니F = W2+b2σ(W1x+b1)라고 생각하면 될 것 같다. 또한 위 식을 구현하기 위해서는 F와 x를 같은 차원으로 맞춰주어야 한다.
만약 F에서 output size가 x size와 달라졌다면 linear projection으로 차원을 맞춰 줄 수 있다.
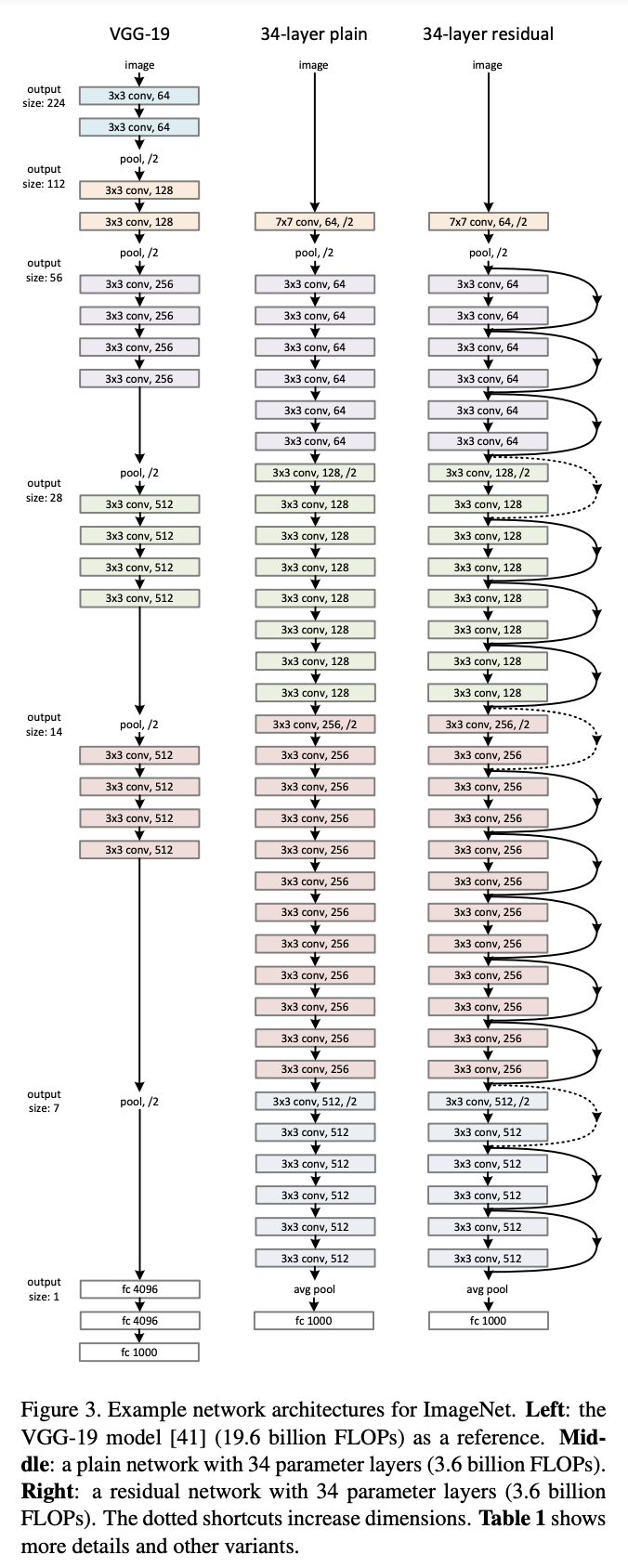
Network Architectures
plain net과 residual net을 테스트한다.
Plain Network
plain baseline은 주로 VGG net에 영감을 얻어 만들어졌다. 합성곱 레이어는 3x3 필터와 2개의 규칙으로 설계되었다.
i) 같은 output feature map size와 같은 크기의 필터
Ii) 만약 feature map size가 절반으로 줄어들면 필터 크기가 2배로 늘어나 시간 복잡도를 보존한다.
합성곱 레이어에서stride 2로downsampling을 하고,
모델의 마지막엔 global average pooling layer, 1000-way의 fully-connected layer, softmax를 사용했다.
34개의 레이어로 되어있으며, 이 모델은 VGG net보다 필터가 많고 복잡도가 낮다. (VGG-19의 18% 정도의 연산량)
Residual Network
Plain Network를 기반으로 하며 shortcut connection이 추가되었다.
Residual Network는 input과 output을 같은 크기로 맞추어 주어야 한다. 그렇게 하기 위해 2가지를 고려해 볼 수 있다.
(A) zero padding을 추가하여 사이즈를 맞춘다. 해당 방법은 파라미터가 추가로 발생하지 않음.
(B) projection을 이용하여 사이즈를 맞추어 준다.
Implementation
구현 방법과 파라미터 설정에 대하여 설명한다.
- 224x224 size의 데이터를 사용한다.
- batch normalization을 이용한다. (conv net과 activate 사이에)
- Initialize Weights
- SGD
- mini-batch 256개
- learning rate 0.1
- iteration 60 x 10^4
- weight decay 0.0001
- momentum 0.9
- dropout은 사용 안 함
Experiments
ImageNet Classification
Plain Network.
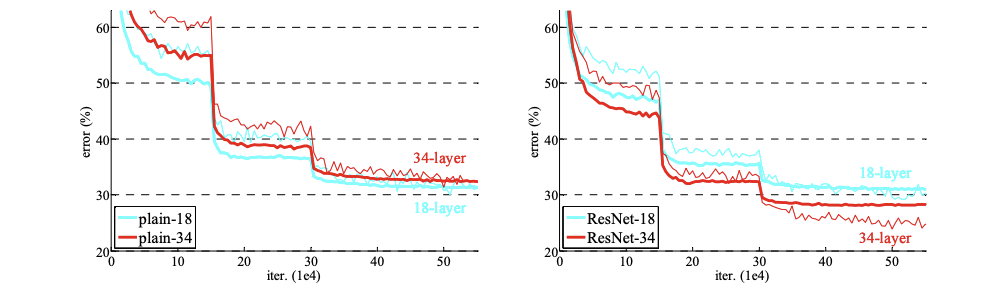
plain net의 경우 이전의 결과에서 실험 결과에서34-layer가 18-layer보다 더 성능이 안 좋은걸 확인했었는데 이는 Batch normailization을 사용한 결과이기에 vanishing gradient 때문이라고 보기 어렵다.
아래 결과를 보면 plain은 34-layer가 더 낮은 성능을 보이는 반면 ResNet은 34-layer가 더 높은 성능을 내며degration문제가 어느 정도 해결된 것이 관측 가능하다.
ResNet.
resnet의 모든 shortcuts에 identity mapping을 이용하고 사이즈를 맞추기 위해 zero padding을 사용한다.
그렇기에 다른 추가 파라미터가 없다. 위에서 말한 (A) 방법을 사용함.
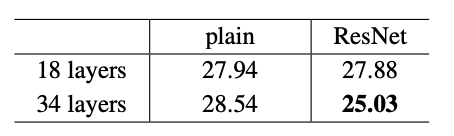
1. 34-layer resnet이 18-layer resnet 보다 더 높은 성능으로 degration문제를 잘 잡았다.
2. plain과 비교했을 때 34-layer는 성공적으로 training error를 줄였다.
3. 18-layer의 두모델은 정확도는 비슷하지만 더 빠르게 수렴한다. SGD를 이용하여 수렴할 때 Plain보다 ResNet이 더 좋은 성능을 낸다.
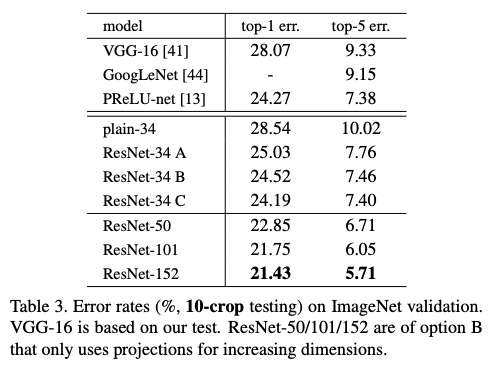
Identity vs. Projection Shortcuts.
Identity 방식으로 해봤으니 이번엔 projection shortcuts방식으로 해본다.
아래 표에서 ResNet-34의 A, B, C 방법을 비교한 것을 보자
(A) 현재까지 봤던 zero padding으로 차원을 증가시킨 방법이다. 이 방법은 추가적인 파라미터가 필요 없다
(B) projection shortcuts를 이용하여 차원을 증가시킨 방법이다. 다른 shortcut은 identity
(C) 모든 shortcut이 projection
위의 표를 보면 C > B > A 순의 성능을 확인할 수 있다.
A는 zero padding에 대하여는 잔차 학습이 이루어지지 않기에 B보다 성능이 약간 낮고
C가 B보다 projection shortcuts에 extra parameters가 많이 들어가기 때문에 성능이 더 높다.
= degradation problem의 문제의 해결에 projection shortcuts이 필수적이지 않다는 것을 말하려고 한다.
그래서 해당 논문에서는 C 모델을 사용하지 않는다.
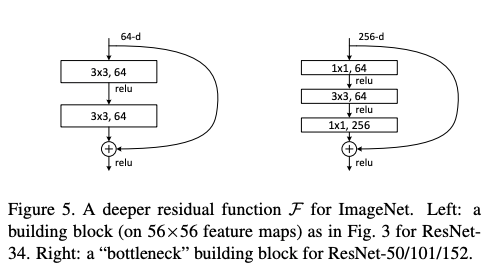
Deeper Bottleneck Architectures.
아래는 deep 한 net을 설명한다.
위 모델에서는 학습시간을 고려하여 Bottleneck 구조를 사용한다.
각각의 잔차 함수는 2개 대신 3겹으로 쌓는다. 모양은 오른쪽 그림과 같은 구조로 이루어져 있다.
1x1은 차원을 감소시키고 복원하는 역할을 하여 3x3이 더 적은 입력과 출력을 갖게 한다.
이를 통해 기존과 비슷한 복잡성을 유지할 수 있다.
50-layer ResNet.
2-block인 34-layer를 -> 3-block으로 바꾸어 50-layer로 만들었다.
(B) 모델을 이용했다.
해당 모델은 3.8 billion FLOPs
*플롭스(FLOPS, FLoating point Operations Per Second)는 컴퓨터의 성능을 수치로 나타낼 때 주로 사용되는 단위이다.
101-layer and 152-layer ResNets.
3-layer를 더 쌓아봤다.
해당 모델은 11.3 billion FLOPs
여전히 VGG모델들보다 복잡성이 낮다
* VGG-16/19 nets (15.3/19.6 billion FLOPs)
이렇게 만든 ResNet은 34-layer 보다 확실하게 높은 성능을 보인다.
Comparisons with State-of-the-art Methods.
6개의 각기 다른 깊이의 모델을 앙상블 하여 test set에서 3.57%의 top-5 error를 보였다.