2016 맥북 13 (2017년 고등학교 2학년 산학일체형도제학습 사업단에서 졸업까지 대여 ~ 2018년 초까지 썼음.)
2018 맥북 프로 15 (2019년 대학교 1학년 부모님이 맥북 사줌 ~ 2020년 중반 아빠 돌려 줌)
2019 Intel 맥북 프로 16 (2020년 대학교 2학년 예비창업패키지 창업 사업비 구매 ~ 2025년 초반까지 씀)
2025 맥북 프로 16 (2025년 초 그냥 생으로 샀음!)
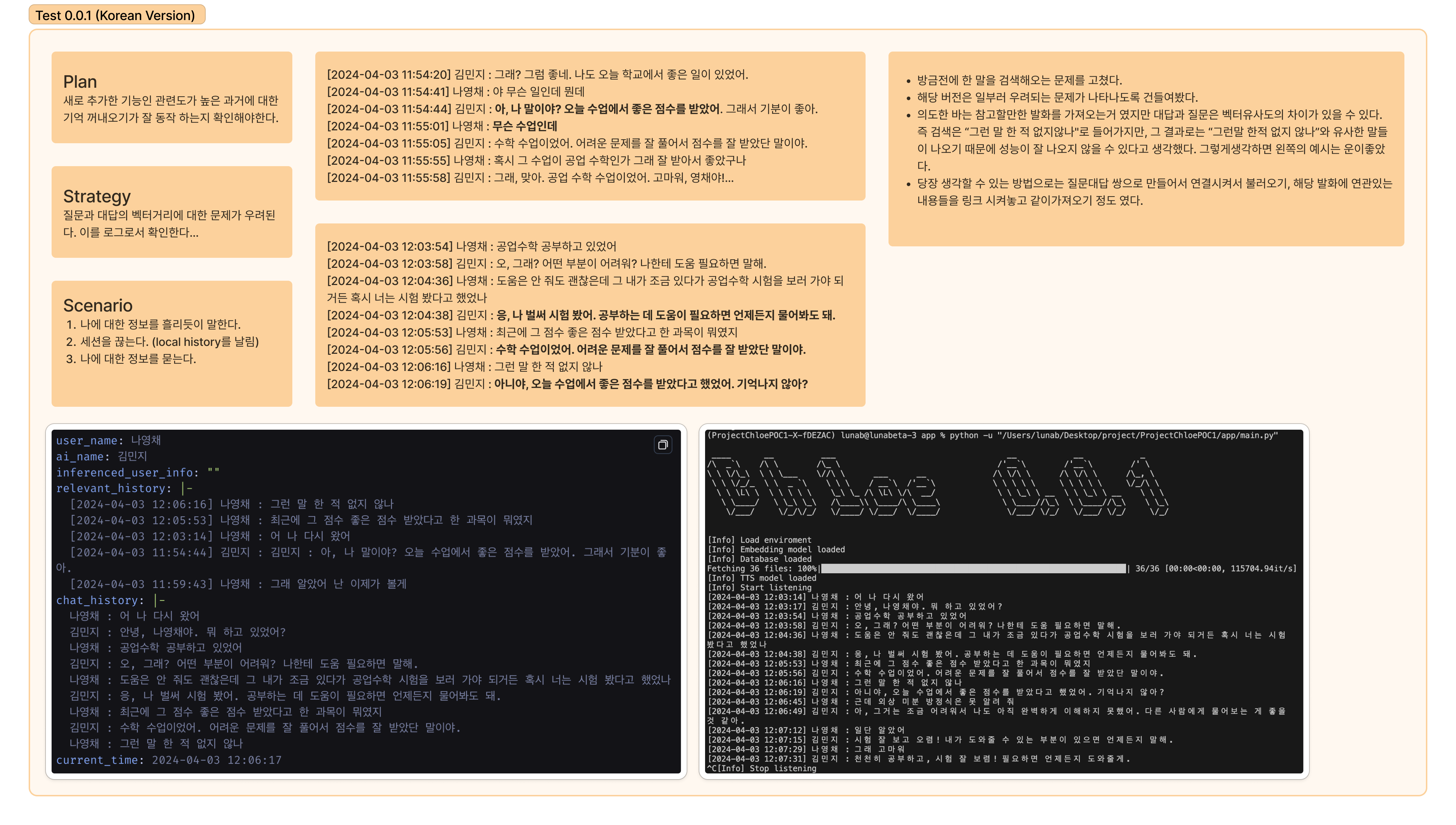
목표
이번 맥북은 그 어느 때 보다 정돈되게 운영해보려고 합니다!
Chrome
일단 누구보다 빠르게 크롬을 설치했습니다.
개발자라면, 제발 크롬.
Visual Studio Code
그 다음 뭘 설치할까 음... 고민 많이했는데, VS Code가 당연 그 다음이겠다 싶었습니다.
설치 한김에 Copilot도 연결 Extension은 나중에 해야겠습니다.
Docker Desktop
우선순위 역시 도커죠 바로 도커 설치했습니다 굳이 CLI로 할필요 절대 없죠?
https://docs.docker.com/desktop/setup/install/mac-install/
ChatGPT
그 다음에는 현재 정말 많이쓰고있는 이 녀석을 써보려고 한다. 드디어 Intel mac에서 벗어났으니 Silicon의 혜택을 누려보자고요.
https://openai.com/chatgpt/desktop/
이야 이거 신기하다 좋네
Slack
최근 자동화 프로젝트를 하고있어서 진행상황이나 실시간 보고를 받기위해 필요한 Slack도 설치하겠습니다.
카카오톡
음 이건 그래도 깔긴 해야지
아... Ollama를 설치할까말까... 그냥 Docker에다 설치해서 쓸까..?
일단 설치안했음
Office
일단 엑셀, 파워포인트, 워드 같은 사무용품(?)들은 설치하는게 맞으니깐
Git
오늘 뭐 하나 설치하려다가 어? GIT이 없네 ㅋㅋ 함
HomeBrew
Git 설치하려고 brew커멘드 쓰는데 어?? brew도 없네 ㅋㅋㅋ함
Notion
NVM
Postman
아 코딩하다가 오잉 postman이 없네 하고 설치.
점차 추가해나갈 예정
## FIGMa
## OBS
'내 생각' 카테고리의 다른 글
| 요즘 내가 하고있는 개발 (일 말고) - 작성중 (0) | 2025.04.30 |
|---|---|
| 2024 SKT Fellowship 6기 과제 설명 & 면접 후기 (1) | 2024.06.03 |
| SAI 세종대학교 인공지능 동아리를 만들고 떠나기까지 (군대감) (0) | 2021.08.16 |
| C.elegans (예쁜꼬마선충)을 이용한 프로젝트에 대한 생각 (0) | 2021.08.04 |