| 날렵한 곰의 차근차근 구현하는 시리즈 입니다. * 구현 연습을 하는 단계에서 쓴 글입니다. |
대충 무슨내용인지는 아는데 구현은 직접하고 싶고 할라니까 아리까리하고 할 때 보면 좋다!
논문과 세부적인 구현 내용은 다를 수 있다.
해당 포스팅은 seq2seq와 attention mechanism의 연결을 최대한 쉽게 이해할 수 있도록 만드는데 목적을 둔다.
포스팅 하단의 구현 코드를 같이 보면서 읽으면 더 이해하기 좋다.
이론
Reference
Sequence to Sequence Learning with Neural Networks : https://arxiv.org/abs/1409.3215
Sequence to Sequence Learning with Neural Networks
Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this pap
arxiv.org
Neural Machine Translation by Jointly Learning to Align and Translate : https://arxiv.org/abs/1409.0473
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
In this paper, we propose a novel neural network model called RNN Encoder-Decoder that consists of two recurrent neural networks (RNN). One RNN encodes a sequence of symbols into a fixed-length vector representation, and the other decodes the representatio
arxiv.org
Summery
Sequence to Sequence Learning with Neural Networks :
RNN의 state를 encoder-decoder 구조로 이용하여 번역모델을 설계했으며, 영어 -> 프랑스어 번역 작업을 실험함.
Encoder 부분에서 나오는 state들은 입력 데이터를 해석(압축)한 context가 된다. 이렇게 만들어진 context를 decoder부분에서 번역해 주는 구조이다.
Neural Machine Translation by Jointly Learning to Align and Translate :
양방향 LSTM으로 만든 Sequence to Sequence를 encoder-decoder로 분리하고 decoder의 매 step마다 encoder의 출력에서 집중해야할 부분을 결정하고 참고한다.
Abstract
위 두 논문을 참고하여 구현해 보겠다 !
간단하게 그림으로 그려 요약해봤다. 사실 그림만봐도 다읽은거나 다름없다..! 그리느라 너무 힘들었고..!

Seq2seq + attention Start!!
구현
* 구현에 도움이 되는 size를 중점적으로 다룬다
Data
만든 모델이 잘 돌아가는지 확인 시켜줄 "영어 -> 독일어" 데이터셋이다
Attention mechanism은 Decoder에서 출력되는 단어를 결정할 때 Encoder에 입력된 단어들을 얼마만큼 참고할지 결정하는 매커니즘 이다.
그렇기에 visualization에서 Attention mechanism이 잘 돌아가는지 확인하기 위해 중복되는 단어를 넣었다.
그러므로 정상적으로 학습이 된다면 "liebe"를 출력하는 Decoder Cell에서 "love"를 높은 비율로 집중하게 될 것 이다.
데이터는 다음과 같습니다. 많은 양으로 학습하면 훨신 좋겠지만 4개로도 결과는 볼 수 있다.

Preprocessing
다음과 같이 Encoder와 Decoder의 단어 사전을 구축한다.
단어 사전에는 "SOS", "EOS" 같은 특수 토큰들이 포함되는데 "SOS"는 문장의 시작, "EOS"는 문장의 끝을 알리는 토큰이다.

그 다음엔 train_data들을 sequence형태로 변환한다.

source는 그대로 사용하였으며
target에는 앞뒤에 SOS와 EOS를 붙여주었다.

Embedding
Word Embedding
기존에 Pretrained 된 Embedding 모델을 사용해도 좋지만, 여기서는 직접 간단하게 만들었다.
Word Embedding에 대하여 간단하게 설명하자면 단어들의 유사성 대비성 등의 유기적인 특성들을 고려하기 위해 단어를 벡터화 하여 학습시키고 표현하는 기법이다.
embed_size를 2차원으로 설정한다면 다음과 같이 표현 가능하도록 학습된다.
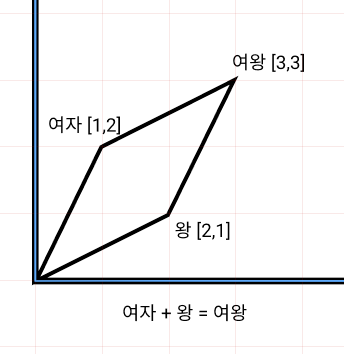
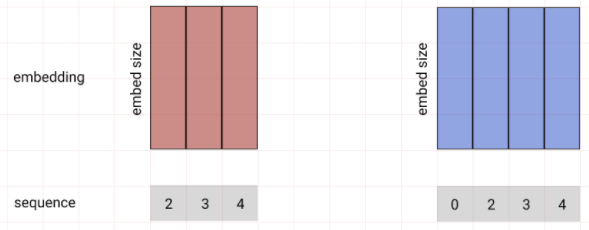
설명의 편의를 위해 2차원으로 설명했지만 저희는 좀더 풍부한 의미를 표현할 수 있도록 4차원으로 설정했다.
embed_size = 4
n_vocab = (encoder 일대 7 decoder 일때 8)
encoder와 decoder 각각의 Embedding레이어가 있어야 한다.
Encoder
Encoder 내부는 Embedding 레이어와 LSTM레이어로 이루어져 있다.
torch.nn.Embedding(src_n_vocab, embed_size)
torch.nn.LSTM(input_size=embed_size, hidden_size=embed_size)
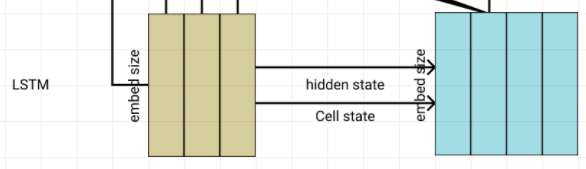
그렇게 하면 Encoder의 LSTM은 i, love, you 3단어를 입력받고 3개의 값을 출력한다.
그리고 Decoder의 LSTM에게 hidden state와, cell state를 넘겨준다.
Encoder에서 넘긴 state들은 encoder에서 압축된 "i love you"의 문맥과 의미 정보를 Decoder에 제공한다.
Decoder
Decoder 또한 Embedding 레이어와 LSTM레이어로 이루어져 있다.
torch.nn.Embedding(tar_n_vocab, embed_size)
torch.nn.LSTM(input_size=embed_size, hidden_size=embed_size)그 뒤에 Decoder는 처음으로 <SOS> 토큰을 입력받고, 전달받은 state를 기반으로 출력을 만든다.
설명의 편의를 위해 저희는 Decoder 두번째 step인 ich를 입력받았을 때로 가정을 하여 설명할것이다.
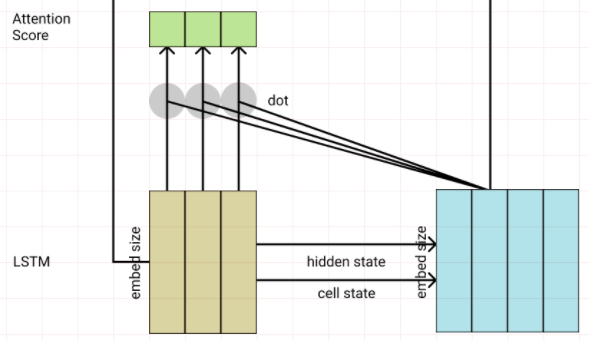
Attention Score
Decoder는 다음 단어를 생성하기 위해 Encoder에 입력된 단어중 어떤 단어에 집중해야 할지 점수를 매긴다.
* 논문에서는 단어 + 단어주변에 focus한 정보 라고 함.
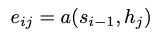
Attention기법은 여러가지 방법이 있는데 그중에 dot-product attention을 이용해보려고 한다.
t 시점의 Decoder의 출력과 모든 시점의 Encoder를 각기 dot연산하여 score를 구한다.
# (src_len, 1, embed_size) (1,embed_size,1)
score = enc_out.matmul(dec_out.view((1,embed_size,1)))
# t 시점 state의 encoder h attention score
# (src_len, 1, 1) = score(hn, stT)다음과 같이 단어별 Attention Score가 나오게 됩니다.
Attention Distribution
Attention Score를 softmax를 적용하여 각 입력에 대하여 얼마나 집중할지를 비율 값으로 만드는 과정이다.
att_dis = F.softmax(score, dim=0)수식은 그냥 단순히 softmax,
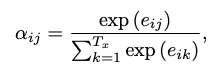
shape의 변화는 없다.
Attention Value
Attention value는 Encoder의 LSTM에서 각 단어들의 출력을 Attention Distribution을 가중치로하여 곱하고 곱해진 값을 더하여 하나의 벡터로 합친다.
# sum((src_len,1,embed_size) * (src_len,1,1))
att_v = torch.sum(enc_out * att_dis, dim=0).view(1,1,embed_size)
# Attention Value
# (1,1,embed_size)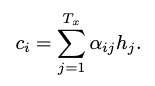
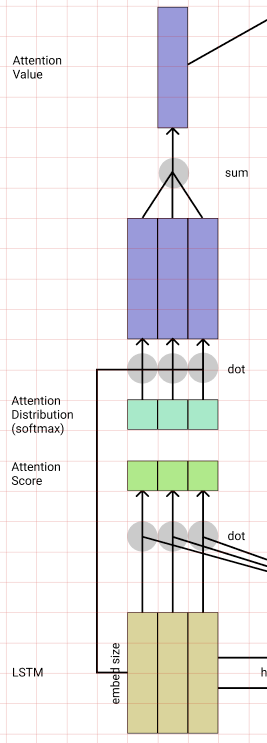
이러한 연산에 어떤 의미가 있을까를 알기쉽게 설명해보자면,
우선 LSTM에서 나온 출력은 각 단어의 의미를 함유하고 있는 벡터이다.
이러한 의미를 Attention Score로 어떤 출력 시점에 어떤 입력을 참고하면 좋을까 점수를 부여한다.
그렇게 점수 매겨진 Attention Score를 가중치로서 곱할 수 있도록 값을 Softmax로 조정한것이 Attention Distribution이였다.
이것을 다시 LSTM에서 나온 출력인 의미 벡터와 곱하는 것은 어떤 의미를 증폭시키겠다. 즉 다음 출력을 만들어 내는데 있어 이 단어(의미)에 초점을 어떤 비율만큼 두겠다 라는 것이다.
"I love you" 를 "ich liebe dich" 로 번역하는 작업을 할 때는
Decoder에 ich를 입력받은 시점에서는 liebe를 출력해야 하기에 love에 대하여 높은 가중치로 집중 해야할 것이다.
또한 번역이라는게 "sweet potato"를 "고구마"로 번역해야 한다면
"고구마"를 출력해야하는 시점에서 "sweet"와 "potato"에 모두 적당한 가중치가 부여 될 것이다.
"그렇다면 Attention Value로 만들기 위해 sum연산으로 합쳐버리면 의미가 소실되는것이 아닌가"에 대한 답변으로는 위의 의미 데이터는 벡터 값이라 더한다고 소실되지 않으니 문제없다.
(당연하지만 너무 적은 embed size에서는 충분한 표현이 불가능해 충돌이 일어날 수 있다.)
Decoder Hidden State
집중해야할 의미를 압축해놓은 Attention Value를 Decoder의 현재 step의 출력과 붙여서 신경망 연산을 수행하여 시점정보와 Attention정보를 해석한 Decoder Hidden State를 만듭니다.
# (1,1,embed_size)
con = torch.cat((att_v, h), dim=2)
# Attention model
wc = nn.Linear(embed_size * 2, embed_size) # (embed_size * 2, embed_size)
tanh = nn.Tanh()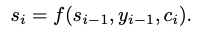
우선 여기까지가 Attention mechanism의 핵심이며 전부이다.
Generate (Output Layer)
단어를 생성하는 방법으로 의미 해석 레이어를 달아 어떤 단어를 선택할지 결정하는 Linear레이어와 Softmax로 단어의 Sequence를 뽑게 만들었다.
# wy (output)
wy = nn.Linear(embed_size, tar_n_vocab) # (embed_size, word_cnt)
# softmax (nll_loss로 연산하기 위해 log_softmax)
x = F.log_softmax(x, dim=2)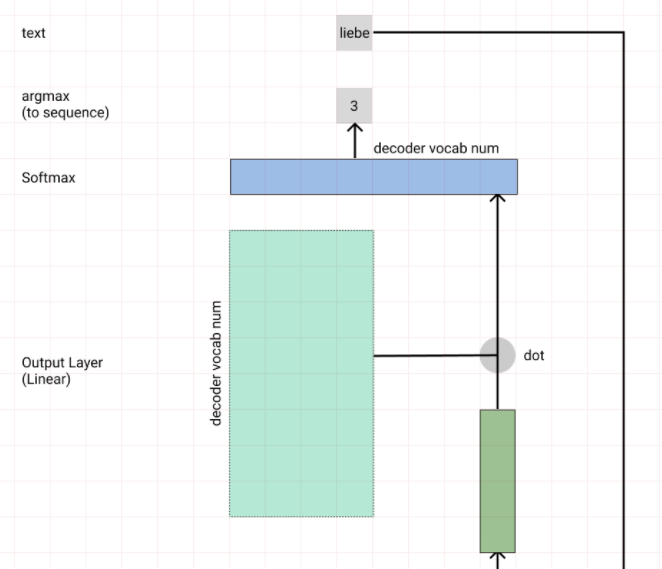
Teacher Forcing
일반적으로 교사강요 라고 해석하는 것 같다.
Seq2seq 모델에서 RNN에서 나온 출력을 다음 step의 입력으로 넣어주는 구조로 출력 리스트를 만들어 낸다. (추론)
이러한 모델을 학습시킬때 step중간에서 원하는 출력이 나오지 않으면 다음 step에 원하는 입력을 주지 못할 것이고 해당 시점 이후로 모든 값이 틀려 버릴 수 있다.
이러한 문제 때문에 RNN의 모든 step에서 입력으로 정해진 값만 입력으로 넣어주는 방법을 교사강요라고 한다.
하지만 이방법을 과하게 이용할 경우, 테스트시 사용될 방식인 추론과 교사강요를 통한 학습의 생성 방식의 차이로 Exposure Bias Problem (노출 편향) 문제가 발생한다.
이게 어떤 문제인지 조금 상상해보자면 Embedding된 단어의 의미를 이용하여 다음 출력에 대한 추론을 해야하고 이는 목표출력과 Embedding 거리와 가까운 출력을 낼 수 있을 것 같은데, 그때 이 출력이 입력으로 들어가여 학습하면 해당 주변의 단어에 대하여 유연한 추론이 가능 할 것이라고 생각된다. 그렇기에 Teacher Forcing을 이용하면 이러한 유연성을 학습할 수 없다는 문제가 있지 않을까 생각해봤다.
아무튼 이러한 이슈 때문에 랜덤확률로 Teacher Forcing사용을 조절하는 방법을 사용하거나, 정확성이 부족한 초반에만 사용하는 방식등이 있는 것 같다.
하지만 이러한 노출편향 문제가 사실 별로 큰 영향을 끼치지는 않는다는 논문이 이후 발표되어 있긴 하다.
- 논문 링크 : https://arxiv.org/abs/1905.10617
Quantifying Exposure Bias for Open-ended Language Generation
The exposure bias problem refers to the incrementally distorted generation induced by the training-generation discrepancy, in teacher-forcing training for auto-regressive neural network language models (LM). It has been regarded as a central problem for LM
arxiv.org
4개의 문장으로 학습하여 사실 Teacher Forcing으로 다 학습시켜도 큰 문제는 없겠지만 70%확률로 적용해서 코드를 짜보긴 했다.
Train
학습은 문제없이 원활하게 진행 되었다. 50 epoch이전부터 이미 100% 학습정확도를 보였다.
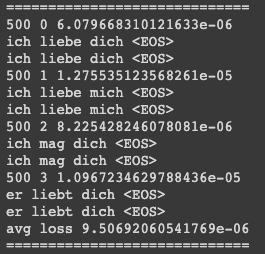
nll_loss로 만들어서 log_softmax사용해야하는데 그냥 softmax 사용해서 삽질했었다. 왠지 loss가 안떨어지더라!
Evalutate
4개의 문장다 추론에서도 완벽한 정확도를 보였다.
Attention이 잘 작동했는지를 검증하기위하여 Decoder의 모든 시점에서 계산된 Attention Distribution을 붙여서 시각화했다.

ich 를 추론하기 위해서 i 에 집중했다. (GOOD!)
liebe 를 추론하기 위해서 love 에 집중했다. (GOOD!)
dich 를 추론하기 위해서 you에 집중했다. (GOOD!)
다른 케이스에 대하여도 좋은 결과를 보였다. (이것은 학습데이터가 많을 수록 단어의 연관성을 더 잘 학습하여 확실하게 나올 것이다.)


Discussion
구현은 이틀걸렸다. 대략 8시간 한것 같다.
포스팅도 이틀걸렸다. 대략 20시간 한것 같다.
글쓰는게 쉽지 않은것 같다.
논문읽고 생각한부분, 상상한 부분 모두 적어봤다.
Repository
https://github.com/lunaB/Pytorch-Study/blob/master/14_seq2seq_attention.ipynb
QnA
- 22.06.12 추가
댓글에 22.06.04에 올라온 질문이 하나 올라와서 답변 남깁니다.
첨부해둔 코드에서 Encoder의 forward 함수에 x를 리턴하지 않게 코드를 짰는데, 재대로 동작하는지 여부가 질문 내용이였습니다.

위의 Encoder 코드는 RNN구조로 다음 State에게 주는 hidden state와 출력으로 나오는 output state가 동일합니다.
그렇기에 필자는 Encoder는 h를 리턴하게 만들고,
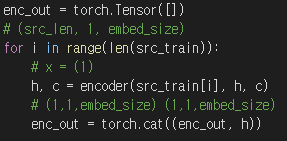
아래와 같이 사용하여 output과 nextState 둘다 사용할 수 있게 했습니다.