+ 2022.06.04 추가함
2016년
친구를 대신하여 대화상대가 되어 줄 수 있는 대화 봇을 만들 수 없을까 생각하며, 데이터베이스, 음성 생성 엔진 기반 대화봇을 만들었었다.
2019년
진짜 사람처럼 SNS를 관리하고 이용하는 인공지능을 만들어 보고자 생각했었다.
실제로 페이스북 같은 인스타그램 계정을 운영하면서 캐릭터 컨셉에 맞는 게시물을 올리고 채팅을 칠 수 있다면 분명 재밌을 것 이라고 생각했다.
2020년
AI분야로는 많이 부족한 나에겐 일단 AI를 SNS에 올릴 수 있는 플랫폼 코드를 구현하며 SNS관련 API를 숙달했다.
2021년
20년도 초 부터 운영해 오던 인공지능 동아리에서 조금이나마 AI에 대한 지식을 쌓았고, 무작정 챗봇 개발에 돌입했다.
그렇게 공부도중 9월 대한민국 육군 특공대에 입대를 하게 되었다.
2022년
조금씩 짬내서 이렇게 글도 쓰고 프린트한 논문들도 가끔씩 읽고 있다. (정말가끔)
2023년
전역예정이다.
오픈 도메인 챗봇 만들기 정리해보자!
우선 필자는 많은 개발자들이 그렇듯 독학을 통해서 공부와 포스팅을 하고있고,
스스로도 전문성은 많이 떨어질 것 이라고 인지하고 있다.
그렇기에 [한국어 오픈도메인 챗봇] 시리즈는 재미로만 보면 좋을 것 같다.
뭘 만드려고 하나
필자의 최종적인 목표는 AI 캐릭터를 만들어 내는 것이다.
이 프로젝트는 그중 대화 부분에 해당되는 부분을 공부하고 구현해 보려고 한다.
나는 오픈도메인 챗봇을 만들기를 희망한다.
챗봇은 크게 이렇게 2개로 나뉘는 것 같다.
1. task oriented chatbot
2. open domain chatbot
이 두개를 간단히 설명하자면,
1번은 목적 지향 대화 챗봇으로, 보험추천 챗봇 같은 문제 해결에 중심을 두고 있는 챗봇을 말하고,
2번은 오픈된 대화주제 챗봇으로, 세상에 존재하는 모든 것을 대화 소재로 하는 대화가 가능한 챗봇을 말한다.
나는 여기서 2번의 open domain chatbot을 만들어보기를 희망하고 있다.
위에 설명한 것 과 같이 많은 범위를 포괄 해야함으로 넓은 범위의 지식을 알고 여러가지 상황에 flow대로 대처하는 것이아닌 유연하게 대처가 가능한 챗봇을 만들 수 있어야 한다.
어떤 기술이 필요할까?
섬세한 챗봇을 만들기 위해서는 너무나 많은 기술을이 필요하고, 특히 언어에 대한 분야는 아직까지도 상당히 난이도가 높다고 평가 되는 것 같다.
어려운 점.
챗봇 만들기를 준비하면서 개인적으로 어려웠던 점을 떠올려봤다.
첫번째로는 채팅 데이터를 얻는것이 가장 어려운 점이라고 생각했다.
한국어 채팅데이터와, 원하는 형태로 라벨링된 대화 데이터를 얻을 수 있는곳은 거의 없었고, 영어 데이터 조차도 찾기 힘들 정도였다.
- 이러한 부분은 역할놀이나 컨셉 랜덤체팅을 지원하는 작은 놀이 웹사이트를 만들어 데이터를 수집해 보면 어떨까 생각도 해봤었다. (라벨링 된 데이터를 얻기 좋다)
- 소설이나 연극 대본 데이터를 잘 처리해서 라벨링된 pair 데이터로 이용할 순 없을까 생각도 해봤다.
두번째로는 학습 리소스와 시간인 것 같다.
현존하는 생성모델들은 거대한 파라미터 수와 방대한 양의 학습데이터를 사용하여 학습하는 경우가 많다. 우리는 이러한 부분을 퓨샷 러닝, 제로샷 러닝, 파인튜닝 등의 기법으로 추가 학습을 최소한으로 하여 모델을 이용 할 수 있긴 하지만, 필자는 훌륭한 학습환경을 마련하기도 힘들고, 긴 학습 시간을 넉넉히 기다리는 것도 쉽지 않다.
세번째로는 난이도가 높다.
개인적인 생각이긴 하다만, AI입문자가 하기에는 높은 난이도의 영역이라고 생각 된다. 현재 연구가 활발하게 진행되고 있다지만 여전히 많은 한계들이 발목을 잡고 있는 상황인 것으로 알고있다. (2021.06) 또한 고성능의 최신 논문이 나왔다 할지라도 리뷰나 구현체 없이 따라해볼 능력까지는 나에게는 아직 조금 어려운 것 같다.
목표.
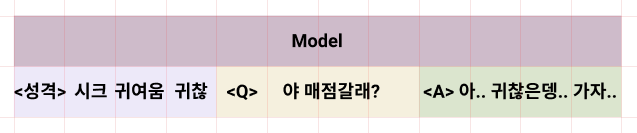
나의 목표는 감정 묘사와 페르소나 적용이 가능한 챗봇을 만드는 것이지만,
질질 끌기보다는 최대한 가성비 넘치는 방법을 찾아 공부하고 개발하여 빠르게 결과를 보고 피드백 할 수 있는 방법으로 진행 해 보고 싶다.
로드맵
- 챗봇
- 메모리 장착
- 페르소나 장착
- 일관성 장착
- 이벤트 장착
- 플랫폿
- 플랫폼 연결
- 이벤트 장착
※ 쓰고나니 하나같이 현 최신 챗봇 연구분야에서도 어려워하는 목표들이다.
최근 읽은 논문들에 의하면 상당히 가성비 넘치는 방법이 많아 보인다. 완벽하진 않지만, 종종 몇번의 소름돋는 짜릿함을 선사하는 대화를 해주는 AI를 만들 순 없을까?
최대한 어렵지 않은 기술들을 잘 엮어서 만들어 보고 싶다.