
서론
오픈 도메인 챗봇 개발이라는 목표를 달성하기 위해 많은 용량의 대화 데이터를 확보해야 하지만,
한국어로 된 오픈 도메인 챗봇을 상당히 얻기 어려울 뿐더러,
핵심을 언급하지 않는 적당한 대답을 매핑하여 출력되도록 하지도 않을 것이다. (그렇게 하기도 힘들다)
본론
그래서 카카오톡 로그를 좀 이용해보면 어떨까 생각했다.
마침 최근에 카카오톡 로그 분석같은 것도 했어서 더 괜찮을 것 이라고 생각이 들었다.
데이터 수집과 가공에 대한 이야기를 쓰려 했지만 왜 이런 데이터를 수집해봤냐를 기록하기 위해서 생각해봤던 아이디어도 같이 적어보려고 한다.
우선 이전에 리뷰했던 아래 논문에 의하면
[논문 리뷰] Hello, It’s GPT-2 - How Can I Help You? Towards the Use of Pretrained Language Modelsfor Task-Oriented Dialogu
날렵한 곰의 간단 논문 리뷰 시리즈 입니다. * 논문 읽는 연습을 하는 단계에서 쓴 글입니다. * 참고할만한 한글리뷰가 없이 작성해서 조금 미숙 할수 있습니다. * 자연스러운 번역을 위해 다듬은
luna-b.tistory.com
아래와 같은 구성으로 transformer의 입력에서 대화의 상태를 값으로써 입력할 수 있다.
그것은 대화에서 나왔던 흐름 상태와 외부에서 참고할 데이터의 상태 2가지로 이용하는 모습을 보였다.

그렇다면 이를 이용하면 아래와 같은 입력도 가능 할 것 이라는것이다.
더 나아가서는 성격 state앞에 이전 대화 기록을 붙이면 멀티턴 까지도 기대할 수 있지만.
우선 이정도로 잡고 가봤다.
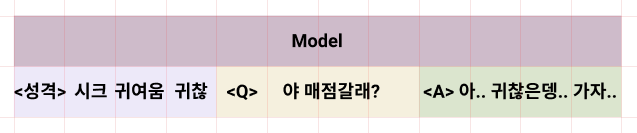
나는 이러한 형식에 맞는 데이터를 수집하기 위해서
대화 데이터셋 이면서, 성격을 알 수 있는 인물 데이터를 모으려고 해봤다.
데이터 수집 접근 방법에 대하여 소개해보겠다.
특정 소설 1개의 대본정보를 크롤링한 뒤 인물에 대하여 직접 성격 라벨링을 진행합니다.
아래와 같이 라벨링을 진행한뒤 대화 데이터와 함깨 성격 데이터를 이용하는 것 입니다.

이렇게 하면 성격을 섞어서 여러개의 성격을 만들어낼 수 있지 않나 생각 했습니다.
물론 학습량과 데이터가 좀 많아야 겠지만요
첫번째로 접근한 방법은 소설 데이터셋이다.
네이버소설을 크롤링 해서 사용해 보려고 했지만, 크롤링에서 인물을 특정할 수 있는 키가 애매하기도하고 서사와 대본이 섞여있어서 애매한 부분도 있었다. 그리고 소설을 크롤링.... 찜찜하기그지없다.
두번째로 접근한 방법은 드라마 대본이다.
장점은 일정한 형식으로 서사와 대본이 정확히 분리되어있다. 또한 무료로 풀려있는 대본도 있었다. 드라마"W"
단점은 거의 한글 파일로 되어있다. (물론 변환기를 사용하면 되긴 하지만..)
세번째로 접근한 방법이 카카오톡 데이터셋이다.
이때는 데이터 사용 전략을 바꿔야 했는데, 여러가지 가공하기 어려운 이유가 있다.
메신저 특성상 말이 섞이는 경우가 많다.
가: 야 배고프지 않냐?
나: 와 화학 방금끝남 왤케오래하누
나: 어? 아 배고프지
가: 아 너 화학도 듣냐?
가: 버거킹이나 가자
위 대화를 보면 바로 알 수 있다.
이런경우 적절하게 처리하기도 약간 어렵고,
소설이나 작품을 위해 만들어진 인물이 아닌 실제 사람을 어떤 성격이다 라고 규정짓는 것도 힘들고,
상대에 따라 다른 페르소나를 보이기에 위처럼 라벨링 하기는 쉽지 않다.

그렇기에 위와 같이 구성하는게 더 낫지 않을까 생각했다.
물론 학습 정확도와 활용도는 좀 떨어지지 않을까 생각 하지만 이게 제일 쉽고 편한 방법인 것 같다.
카카오톡 데이터 전처리
나는 맥북을 이용하는데, 데이터를 csv파일로 받아볼 수 있기 때문에 조금더 쉽게 데이터를 처리할 수 있었다.
윈도우는 txt로 주고 형식도 처리하기 어렵다.
이모티콘, 사진, 동영상, 삭제된 메세지입니다., 너무긴 메세지, 태그, url
다음 토큰도 염두에 두어야한다.
데이터셋을 가공
데이터셋을 가공하는데는 다음 방법으로 해봤다.

긴 텀의 대화는 이어지지 않는 대화라고 가정하는 것이다.
아, 배고프다 ->>>>>>>>>> 오랜시간뒤 ->>>> 야 뭐하냐, 밥먹는중임
아, 배고프다는 버려지고
A: 야 뭐하냐
B: 밥먹는중임
이 데이터셋으로 들어가게 되는것이다.
결론
암튼 여기까지는 가설이고
사실 이렇게 만들고 모델을 만들어 테스트를 해봤지만
학습량이 부족한지 데이터가 부족한지 여러가지 문제로 인해
신기하다.. 대박이다.. 싶은 성능은 안나온다.
다음글은 시도와 분석에 대하여 쓰지않을까 싶다.
'B급 개발물 > 한국어 오픈도메인 챗봇' 카테고리의 다른 글
| [한국어 오픈도메인 챗봇] 4. Chat GPT 간단 체험 (0) | 2023.03.28 |
|---|---|
| [한국어 오픈도메인 챗봇] 3. 카카오톡로그 기반 1:n 발화모델 개발 (0) | 2021.08.04 |
| [한국어 오픈도메인 챗봇] 1. 기초 지식 공부 (0) | 2021.07.30 |
| [한국어 오픈도메인 챗봇] 0. 사람같은 챗봇 만들기 (0) | 2021.06.29 |