| 진행중인 프로젝트입니다. |
밥을 잘 먹는 유전자를 가진 박테리아를 육성하는 시뮬레이터를 만들 것이다.
이 시뮬레이터는 유전 알고리즘을 기반으로 만들어진다.
실제로 박테리아는 유성생식을 하진 않지만, 유전물질을 교환하여 접합, 교차, 변이를 수행하기도 한다.
< 실제 생명공학의 유전 방법과는 다르다. 해당 알고리즘은 실제 현상을 모방하여 만들어졌을 뿐이다. >
lunaB/Genetic-Algorithm-Simulation
genetic algorithem simulator with HTML5 Canvas and Typescript - lunaB/Genetic-Algorithm-Simulation
github.com
개발 스펙
- HTML5, CSS3, Javascript
- Webpack, Typescript
요약
설계한 구조에 대한 간단한 요약이다.
시뮬레이터 로직은 아래와 같이 구성된다.

유전 알고리즘은 선택, 교차, 돌연변이 3개의 알고리즘을 사용했다.
세대 적합도 평가에서 목표 적합도 이상이 나올 시 루프를 중지하고 테스트를 하며 상태를 확인해 보려고 한다.
개발
시뮬레이터 로직에 대한 간단한 설명과 개발물을 정리한다.
환경 생성
시뮬레이터는 HTML5 Canvas 기능을 이용하여 만든다.
하나의 세대에서 환경은 다음과 같다.
- 배양판
- size: 800*600
- step: 1000
- 배지 (영양분)
- num: 300
- size: 5*5
- 박테리아
- num: 20
- size: 15*15
- gene size: 20
- mutation rate: 15%
- 보상
- 영양분을 섭취했을 때 +1
시뮬레이션
설계 편에서 설명했던 유전자 프로그래밍으로 각각의 박테리아가 움직일 수 있도록 하고.
박테리아에게 닿은 먹이는 해당 박테리아가 먹고 몇 개의 먹이를 먹었는지 저장하게 만들었다.
세대가 처음 시작되면 설계 편에서 언급한 박테리아의 움직임을 프로그래밍하는 "AGC"염기가 존재하지 않아서 움직이지 못하는,
즉 장애를 가진 박테리아들이 존재한다.
세대 초반에는 "AGC"염기를 가진, 움직일 수 있는 박테리아가 높은 적합도를 얻었다. (보상 = 적합도)
하지만 세대 초반만 넘어가면 유전 로직에 따라 거의 모든 박테리아가 "AGC"염기를 가지게 된다.
모든 박테리아가 "AGC"염기를 가지게 된다면 더 활발한 움직임을 코딩하는 염기를 가지도록 진화할 것으로 예상한다.
세대 적합도 평가
세대에 대하여 적합도를 평가하고, 세대의 모든 박테리아에 대한 적합도를 평가한다.
적합도는 박테리아가 먹은 먹이의 개수로 정했다.
300개의 먹이 중에 150개인 절반을 먹는 세대를 만들어 내는 것을 목표로 해보자.
* score: 150 일 때 loop 멈춤.
유전자 선택
다음 세대의 부모가 되어줄 유전자를 선택한다.
유전자 선택 알고리즘은 룰렛 휠 알고리즘을 사용했다.
모든 유전자를 룰렛 위에 적합도의 비율로 공간을 분배하여 그리고 룰렛을 던져 맞춘 유전자를 뽑는 느낌으로 지어진 이름 같다.
각 필자의 코드에서 선택되는 박테리아는 모두 (박테리아(i)의 적합도 / 모든 박테리아의 적합도 합)의 확률로 선택되게 했다.
적합도가 높은 유전자를 높은 확률로 선택하는 알고리즘으로, 적합도가 낮은 유전자가 뽑힐 확률도 남겨 두는 느낌이다.
박테리아의 관점으로 보면 먹이를 많이 먹은 유전자가 자손을 만드는.. 느낌.
유전자 교차
부모로 선택된 박테리아는 자손을 만든다.
선택 연산을 2번 하여 부모 A와 부모 B를 선출한 뒤, 교차 포인트는 랜덤으로 하나 지정하고, 포인트를 기준으로 교차하게 만든다.


직관적으로 이해할 수 있도록 그려봤다.
위에선 1개의 교차 포인트를 두었지만 2개 이상 사용하는 방법도 있다고 한다.
유전자 돌연변이
교차로 나온 자손을 다음 세대에 투입하기 전 낮은 확률로 돌연변이가 일어날 수 있게 한다.
15% 확률로 유전자 돌연변이가 일어나도록 했다.
돌연변이는 보통 반전(reverse) 연산이나 교환(exchange) 연산을 하는 경우가 많은데
위 시뮬레이터에서는 교환 연산만 이용했다.
자손 B가 15% 확률로 돌연변이가 생긴다면, 랜덤 한 두 염기의 위치가 바뀌게 되는 것이다.
새로운 세대 생성
위와 같은 연산으로 세대를 생성하여 다음 세대의 시뮬레이션에 투입시킬 준비를 한다.
다시 환경 생성과 시뮬레이션
다시 먹이를 랜덤으로 깔고
새로운 세대를 랜덤 한 위치에 배치하고
위의 과정을 반복한다.
결과

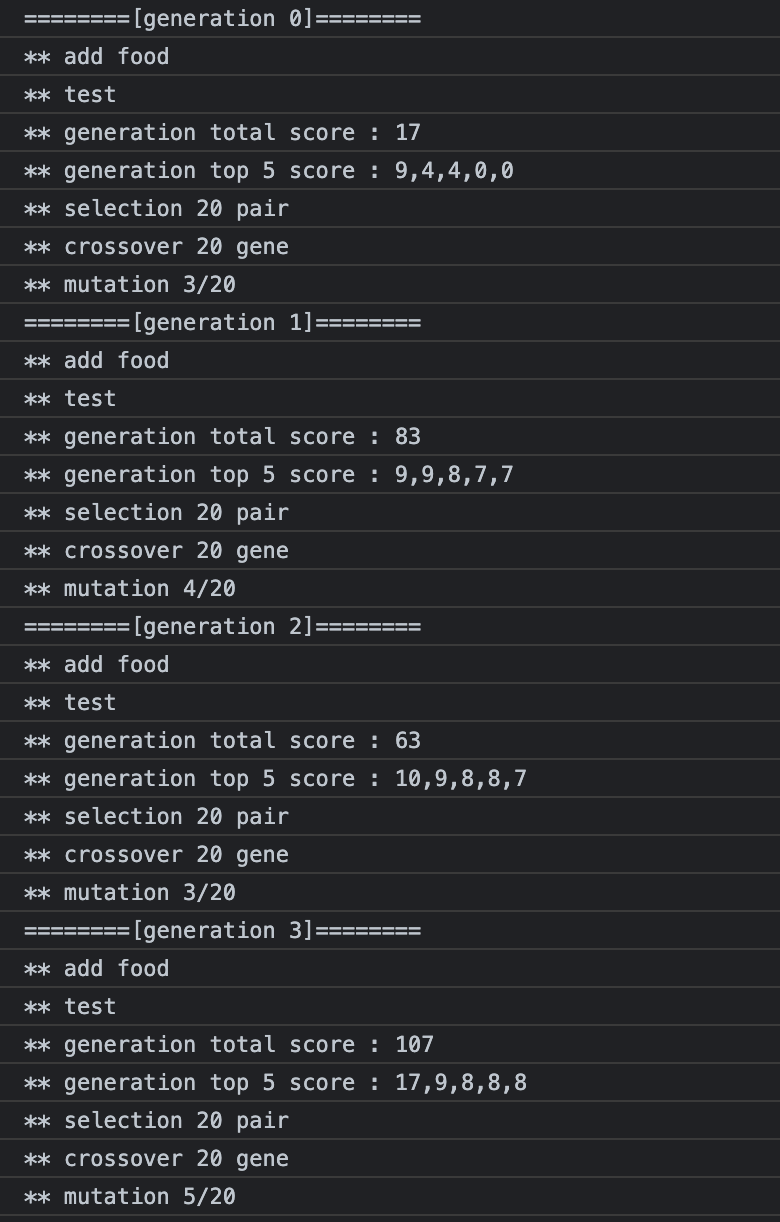


세대가 갈수록 항상 더 높은 적합도를 갖는 박테리아가 나타나지는 않지만, 대체적으로 점점 적합도가 높아지는 경향을 보였다.
그리고 목표한 총적합도 150을 넘는 세대도 만들 수 있었다. 161세대에 172점으로 성공했다.
이동패턴을 프로그래밍하는 "AGC"염기도 가장 앞으로 나온 모습을 볼 수 있다.
분석
성공한 세포의 움직임이다. 얼추 예상했던 패턴과 예상 못했던 패턴이 있었다.
위 세포를 분석해보자면 아래와 같다.
- 진동하며 이동한다.
- 비교적 크기가 작은 먹이를 스쳐서 지나치지 않기 위해 최대한 진동하며 이동하여 더 많은 먹이를 먹을 수 있게 진화한 것이라고 분석했다.
- 옆쪽 방향으로 이동한다.
- 이동은 유전자의 조합을 통해 모든 방향으로 움직일 수 있지만 보통 옆으로 움직이도록 진화했다.
- 세포는 매 세대마다 랜덤 한 위치에 스폰됨으로 대각선으로 이동해버리면 먹이를 거의 먹지 못하고 배양판을 탈출해 버리는 문제가 발생하고, 위로 이동한다면 가로보다 세로 길이가 짧기 때문에 더 적은 먹이를 먹게 될 확률이 크기 때문이라고 분석했다.
- 디테일하게 짚자면 옆쪽 방향으로 각도가 많이 기울어진 대각선이 가장 좋은 듯하다. (이동 가능 거리 + 진동 여부 고려)
- 이동패턴을 프로그래밍하는 "AGC"염기가 앞으로 이동했다.
- 활발하게 움직이는 진화 전략이 선택된 만큼 이동패턴이 복잡할수록 먹이를 잘 먹을 수 있기 때문인 것이라고 분석했다.
다음 모델에서는 어떤 점을 개선해야 할까?
- 처음 기획할 때 예측하길 배양판 밖에는 먹이가 없음으로 진화를 거듭한다면 원을 그리며 움직여 배양판을 쉽게 나가지 않고 최대한 많이 휘젓고 다니게 진화하지 않을까 생각했지만 그러진 않았다.
- 배양판을 나가지 않고 최대한 많이 움직여야 높은 점수를 얻을 수 있을 거라고 생각했다.
- 배양판을 나가서 오래 있을수록 적합도 점수를 깎아볼까?
- 돌연변이 확률을 올리거나, 세대에 완전 랜덤 한 박테리아를 섞어서 넣어볼까?
우선 이 정도 생각해 볼 수 있을 것 같다.
분석편에서 이부분을 더 자세하게 짚어보겠다.








